
Training Agents in CrewAI: A Simple Guide
Want better results from your CrewAI agents? Learn how early feedback and training loops lead to smarter, more reliable outputs.

I’ll be honest, when I first looked at the training documentation for CrewAI, I wasn’t really sure what to make of it.
“…Training? Training what?”
The docs offer a few context clues, like this line:
“Learn how to train your CrewAI agents by giving them feedback early on and get consistent results.”
And under the overview:
“The training feature in CrewAI allows you to train your AI agents using the command-line interface (CLI). By running the command
crewai train -n <n_iterations>, you can specify the number of iterations for the training process. During training, CrewAI utilizes techniques to optimize the performance of your agents along with human feedback. This helps the agents improve their understanding, decision-making, and problem-solving abilities.”
Still a little fuzzy on what it actually does, I decided to explore it myself.
At a high level, training in CrewAI is not just about teaching the model new facts, but also about shaping how your agents think, behave, and make decisions.
Each training iteration runs your agents through a task, captures their outputs, and applies your feedback to refine their reasoning paths, tool usage, and response patterns. Over time, these feedback loops help the agents consistently align with your expectations, reduce repeated mistakes, and adapt better to the kinds of problems you want them to solve.
Recently, I posted about a CrewAI multi-agent research team project that I worked on. If you haven’t seen it, it’s worth checking out here:

Minimal setup and run
Install CLI
uv tool install crewaiInstall deps
crewai installRun once (baseline)
crewai runTrain with feedback (interactive)
crewai train -n <n_iterations> <filename> (optional)Replace
<n_iterations>with the desired number of training iterations and<filename>with the appropriate filename ending with.pkl. I just called it training_output.pkl
Agentic Architecture

Above is a simple illustration of the multi-agent orchestration we designed to test out training. To oversimplify it, we are using the same setup I described in my earlier post about my multi-agent research team. One agent focuses on gathering and structuring relevant information, while the other refines and synthesizes it into a final output.
Training Executed
Senior Data Researcher Agent Training
At this point, we have executed our crew train, have provided the number of iterations (for this example, I just chose one iteration), and now the first agent is being executed as it normally would be as if you were invoking a standard run.
As the agent completes its first run and shows the output, we are given a prompt by the training run illustrated below:
## TRAINING MODE: Provide feedback to improve the agent's performance.
This will be used to train better versions of the agent.
Please provide detailed feedback about the result quality and reasoning process.“Be sure to include something on deep research here as an advancement in 2025 for LLM”
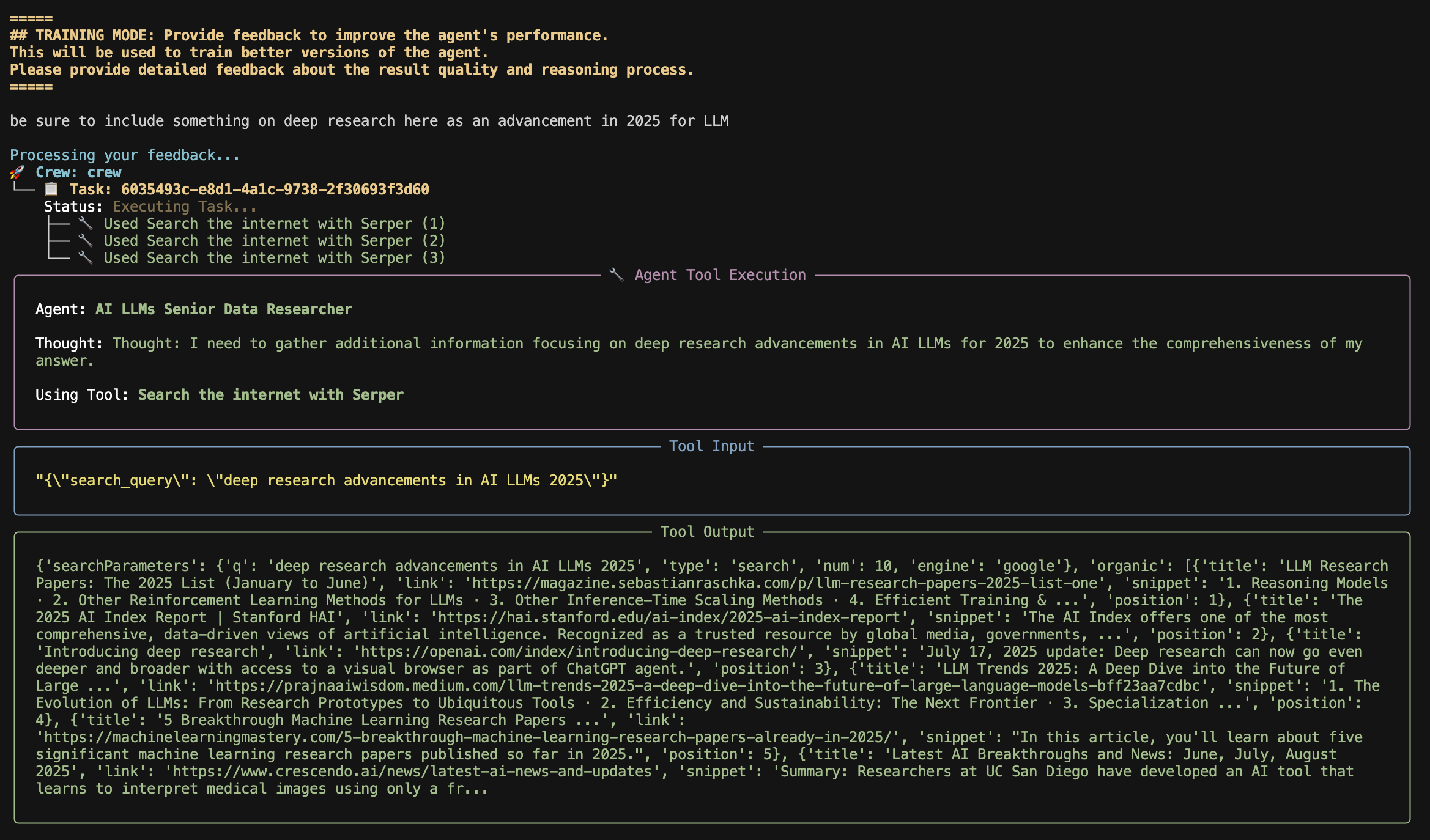
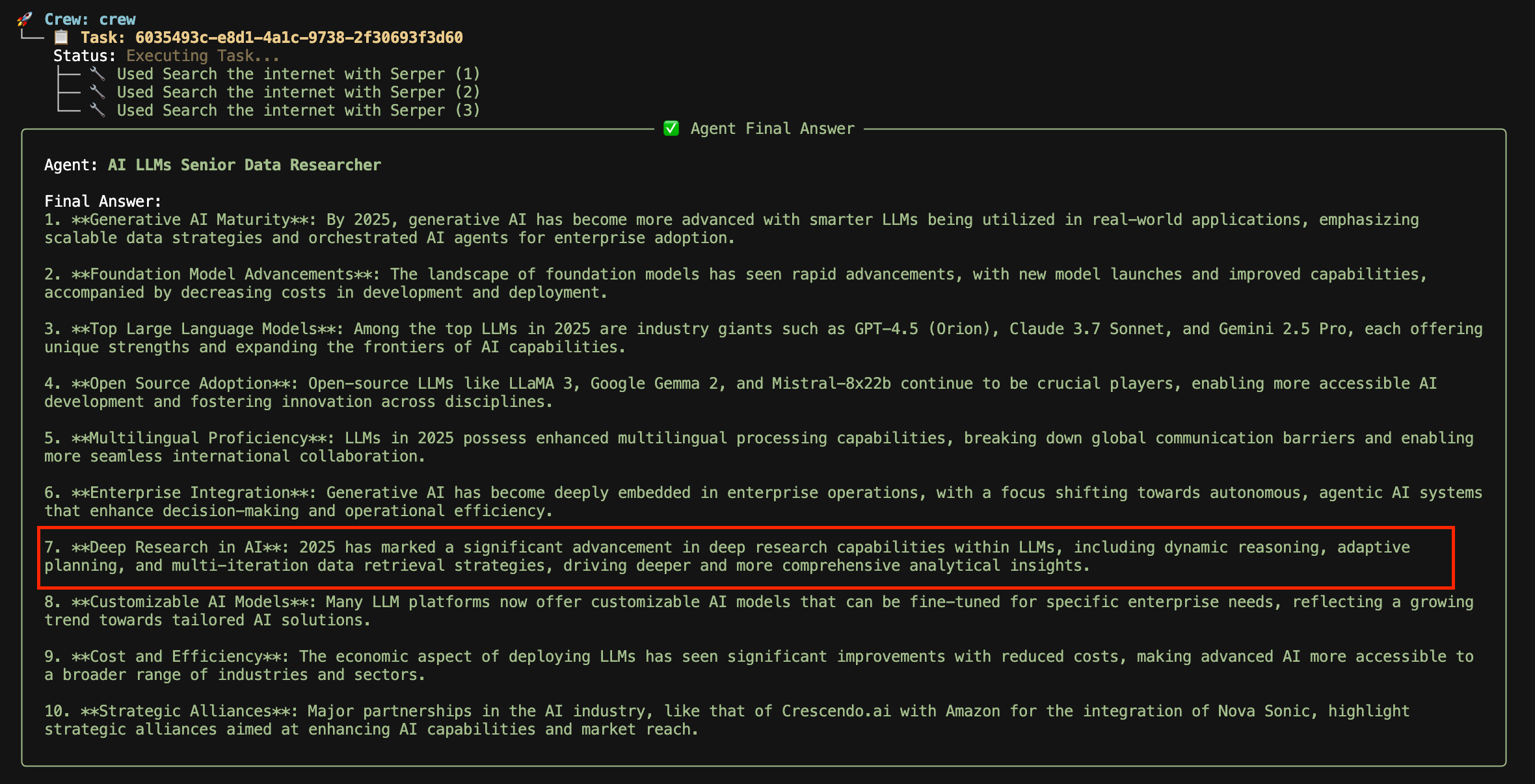
Basically, I noticed that while exploring the top developments of AI LLMs in 2025, the agent skipped over “deep research” entirely. My feedback was to explicitly include it in the results.
As you can see in the capture above, the agent tool execution is now gathering more information about deep research.
Thought: I need to gather additional information focusing on deep research advancements in AI LLMs for 2025 to enhance the comprehensiveness of my answer.
The feedback is now being processed, and the training has come up with a new search query to use with my Senior Data Researcher agent to find out more information on deep research:
"{\"search_query\": \"deep research advancements in AI LLMs 2025\"}"
The agent executes and then as you can see below, adds a section on deep research to its final answer, before we move on and pass off our research to our analyst to review the context and expand each topic into a full section for a report.
Reporting Analyst Agent Training
Now that the Senior Data Researcher task has been completed, the sequential agent flow is now assigning the next task to the Reporting analyst.
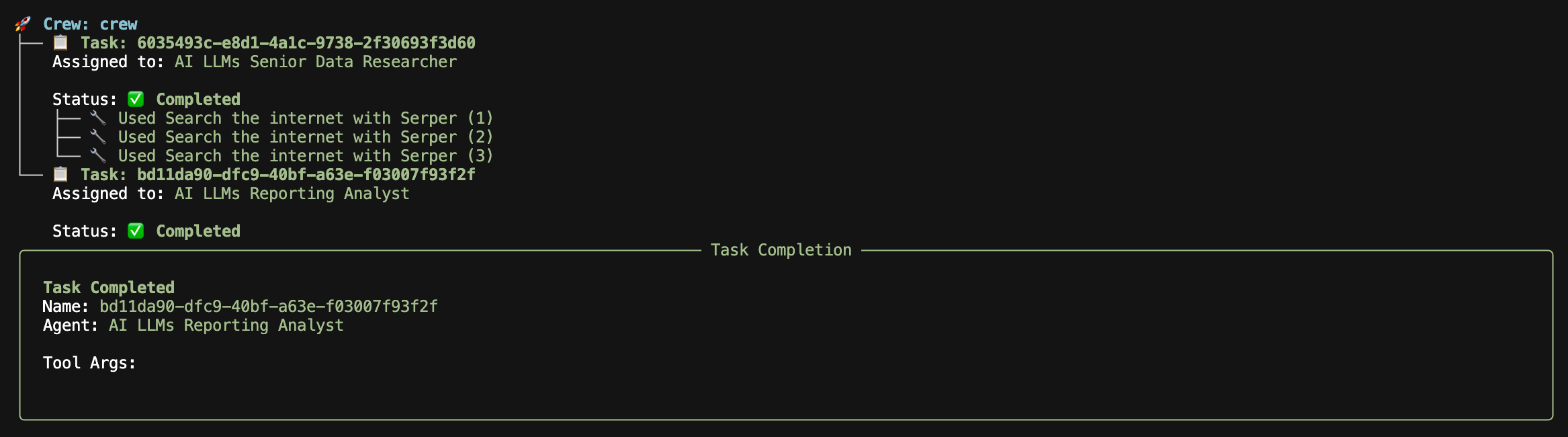
The analyst, just like the senior data researcher, runs through its normal execution flow and provides an output of its report for you to review.
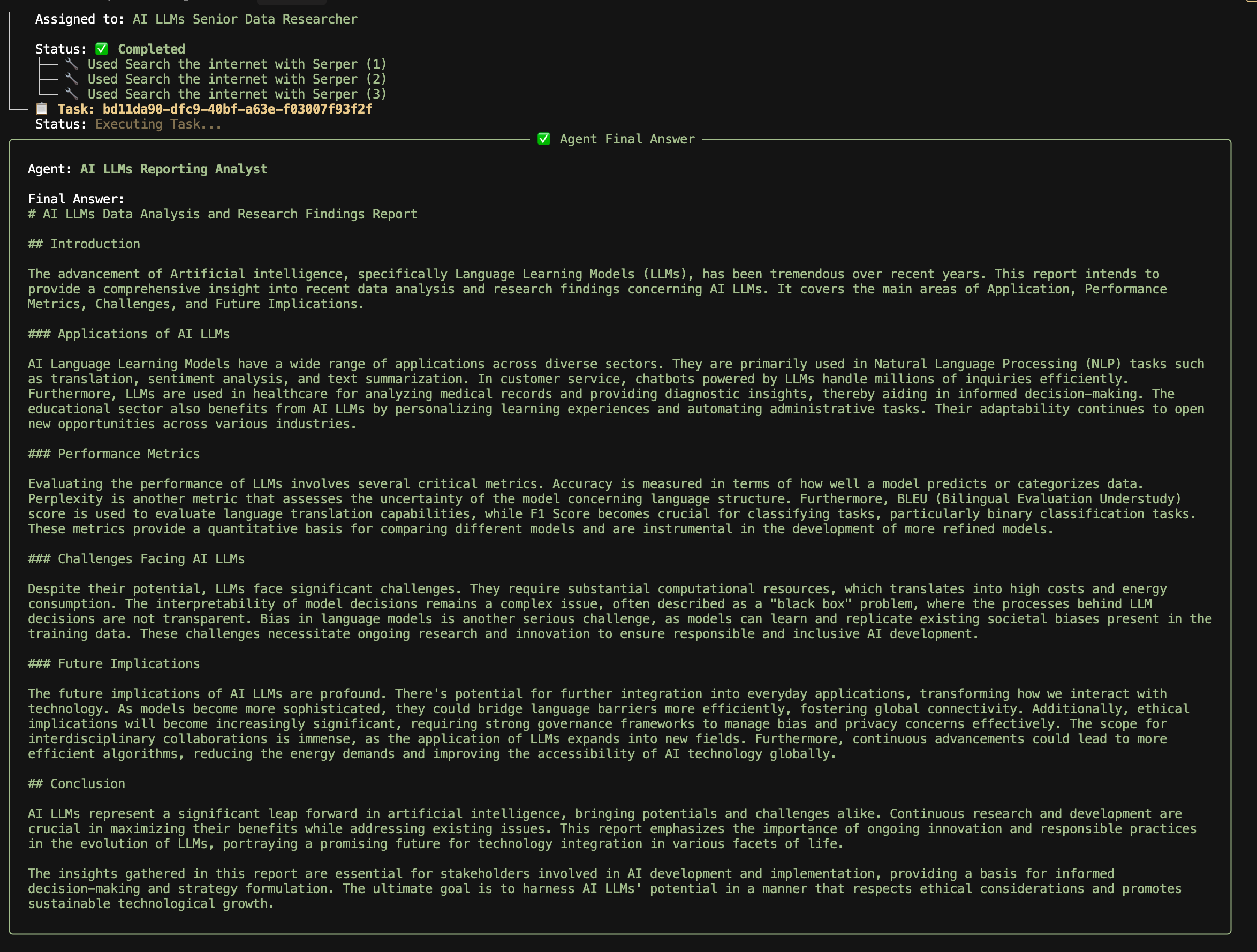
The agent training now gives us an opportunity to provide feedback to the agent’s response:
## TRAINING MODE: Provide feedback to improve the agent's performance.
This will be used to train better versions of the agent.
Please provide detailed feedback about the result quality and reasoning process.I would try to include things from the researcher on ethics of AI, real world use cases that are being solved for by LLMs in 2025 and also any industry trends that we see as far as investments
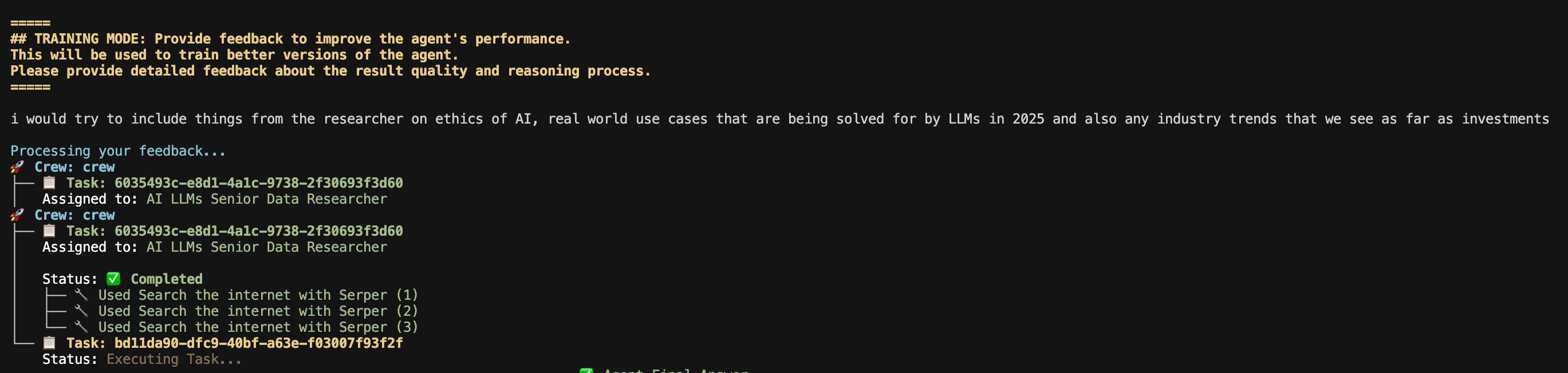
I suggested adding sections on AI ethics, real-world use cases for LLMs in 2025, and notable industry trends.
Just like our Data Researcher agent, the agent training has taken our feedback and applied it to the final output of the Analyst agent’s response.
We can see that ethical considerations, real world use cases and industry trends are now included in the agent’s output.
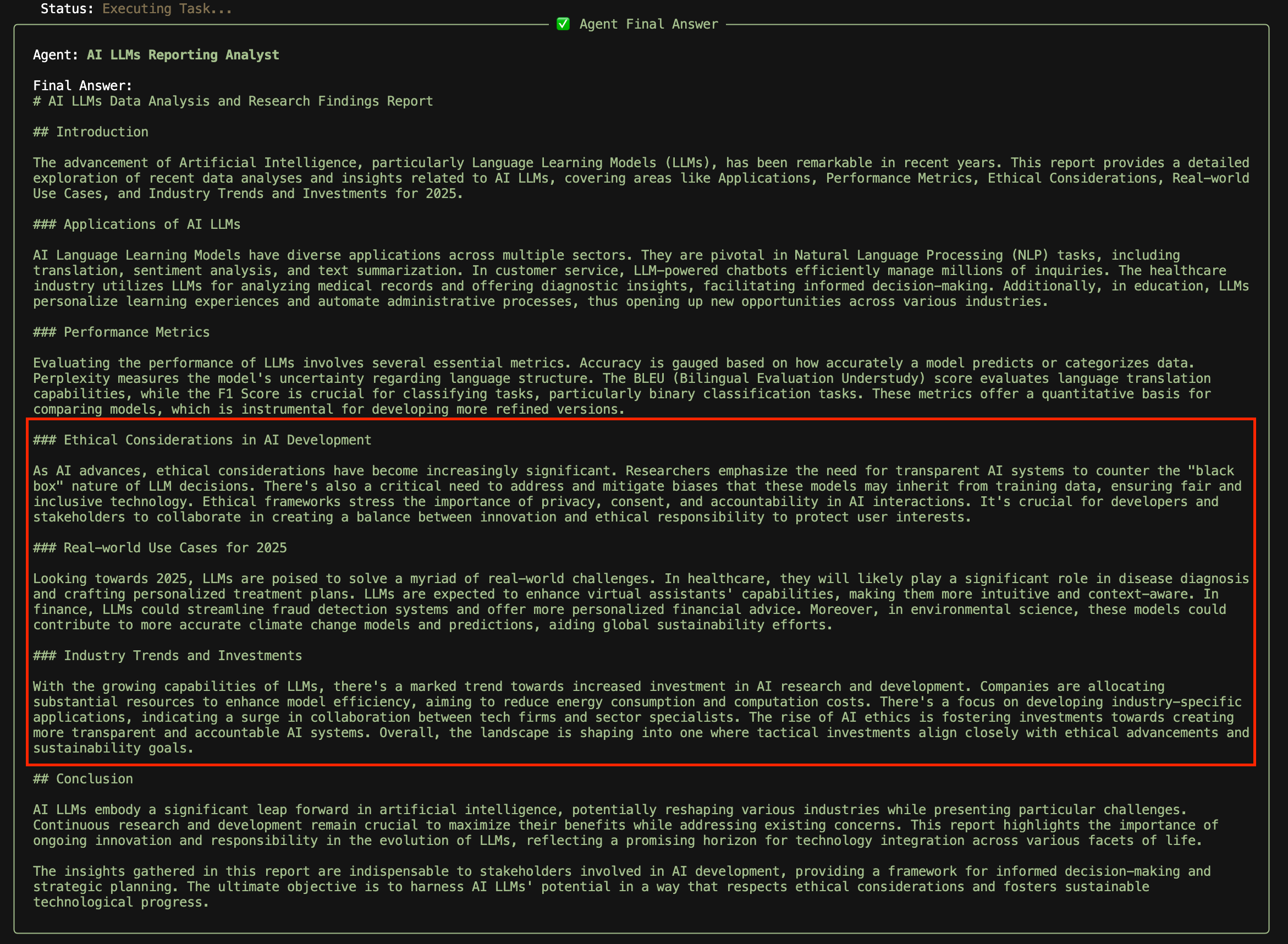
Final Output from Training
Our two agents have now completed their training iterations, incorporating all of our feedback into the agentic workflow. This updated workflow is saved to a .pkl file, which will be used in future runs to augment both the quality and consistency of their outputs. In practice, this means every new task they tackle will benefit from the lessons learned during training, producing richer insights, fewer missed details, and a reasoning process that is increasingly aligned with our expectations. CrewAI’s training mode turns feedback into a lasting performance boost, making each run smarter than the last.