
Recursive Language Models Work, But Not Every Time
Empirical comparison of RLM, RAG, and chunking across 2.2 million tokens with n=30 runs per condition reveals that model selection, retry strategies, and task type matter more than method choice

Executive Summary
This research evaluates Recursive Language Models (RLM) from arXiv:2512.24601 through rigorous empirical testing. We tested two RLM implementations: a Custom RLM we built following the paper’s approach, and the DSPy RLM module (dspy.RLM). We compare both against RAG (Retrieval Augmented Generation) and traditional chunking approaches across multiple tasks and models.
We conducted two layers of testing:
Model comparison: We tested both Custom RLM and DSPy RLM across multiple OpenAI models, including standard models (gpt-4o-mini, gpt-4o) and reasoning models (gpt-5-mini, gpt-5.2, gpt-5-nano). This revealed that model selection is critical: standard models scored 0/6 on aggregation tasks while reasoning models scored 6/6 with identical code and prompts.
Variance testing (n=30): After identifying gpt-5-mini as the best-performing model for RLM tasks, we ran Custom RLM, DSPy RLM, and RAG 30 times each with identical inputs to measure variance. Variance captures how much results differ between runs of the same system, and understanding it is essential for deciding whether to deploy these methods in production.
Key Findings
1. Variance is the story.
Multi-document aggregation revealed significant variance in both RLM implementations. Scores ranged from complete failure (0/6) to perfect accuracy (6/6) across 30 identical runs.
2. Task type determines reliability.
Single-document analysis (one book, deep questions) showed lower variance (std=0.75) than multi-document aggregation (six books, synthesizing across all). Both RLM implementations are more reliable for focused analysis than cross-document synthesis.
3. Model selection matters more than method.
Frontier reasoning models (gpt-5-mini, gpt-5.2) succeeded where standard models (gpt-4o, gpt-4o-mini) failed completely. Same code, same prompts, but 0/6 vs 6/6.
4. RAG wins on consistency.
RAG achieved the most stable results on single-document reasoning (std=0.63), but struggled with multi-document aggregation where systematic coverage matters more than semantic similarity.
5. Cost-variance tradeoff.
DSPy RLM costs ~2x more than Custom RLM but shows lower variance on reasoning tasks.
1. Introduction
The Problem with Long Documents
LLMs face a fundamental challenge: context windows have limits. A 2.2 million token corpus cannot be processed directly. Even 700K token documents strain budgets.
The RLM Promise
Recursive Language Models (arXiv:2512.24601) propose an elegant solution:
Store the full document as a variable in a sandboxed Python environment
Let the LLM iteratively generate code to explore the document
Execute code, return results, repeat
The model searches, slices, and reasons programmatically
Theoretical advantage: Instead of processing millions of tokens at once, the model strategically samples relevant sections.
Our Contribution
The original RLM paper reports single-run results on synthetic benchmarks. We contribute:
Statistical rigor: n=30 runs per condition reveals variance hidden by single-run reporting
Real-world tasks: Literary analysis across 2.2M tokens of classic novels
Method comparison: RLM vs RAG vs Chunking on identical tasks
Practical guidance: When to use each approach
Research Questions
How reliable is RLM? (variance across runs)
Under what conditions does RLM excel?
How does model selection affect outcomes?
What are the cost/quality trade-offs?
2. Methodology
Test Corpus
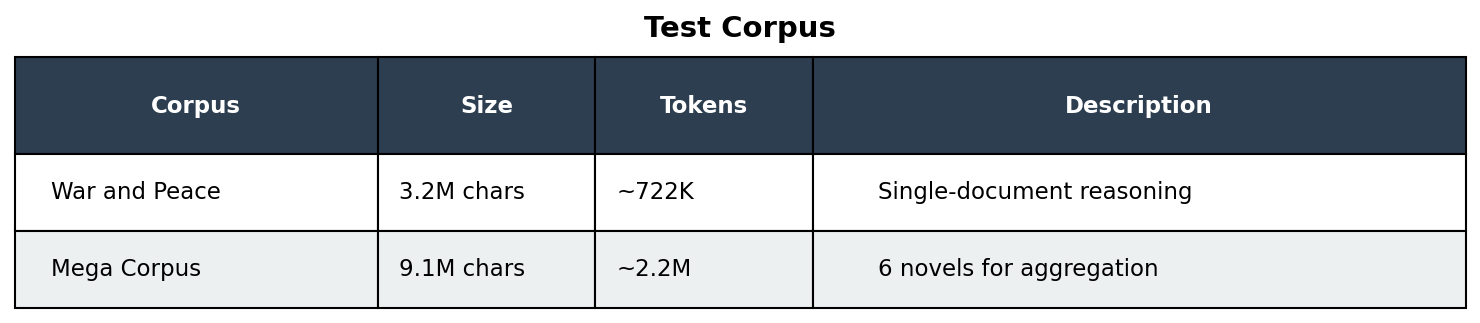
The Mega Corpus combines: War and Peace, Great Expectations, A Tale of Two Cities, Oliver Twist, David Copperfield, and Moby Dick.
Methods Compared

Statistical Design
We ran each condition 30 times with identical inputs.
Why n=30? With 30+ samples, the sampling distribution of the mean typically stabilizes enough to estimate mean and variance reasonably. This is standard in behavioral research for detecting medium effect sizes.
Why temperature=1.0? We wanted to measure natural variability under realistic “creative exploration” settings. Lower temperatures would reduce randomness but wouldn’t eliminate the path-dependence inherent to agentic systems: once the model commits to exploring one section first, its subsequent decisions cascade from there. Temperature=1.0 captures this real-world behavior.
Tasks and Scoring
We designed two tasks to test different capabilities: deep reasoning within a single document, and information aggregation across multiple documents.
Reasoning Task
Corpus: War and Peace (722K tokens)
Question: “How does Pierre Bezukhov’s understanding of happiness change throughout the novel?”
What we’re measuring: Can the model navigate a massive document, find the relevant sections about Pierre’s character arc, and synthesize them into a coherent answer?
Scoring approach: We identified 8 key terms that a comprehensive answer should reference. These are actual names and terms from the novel:
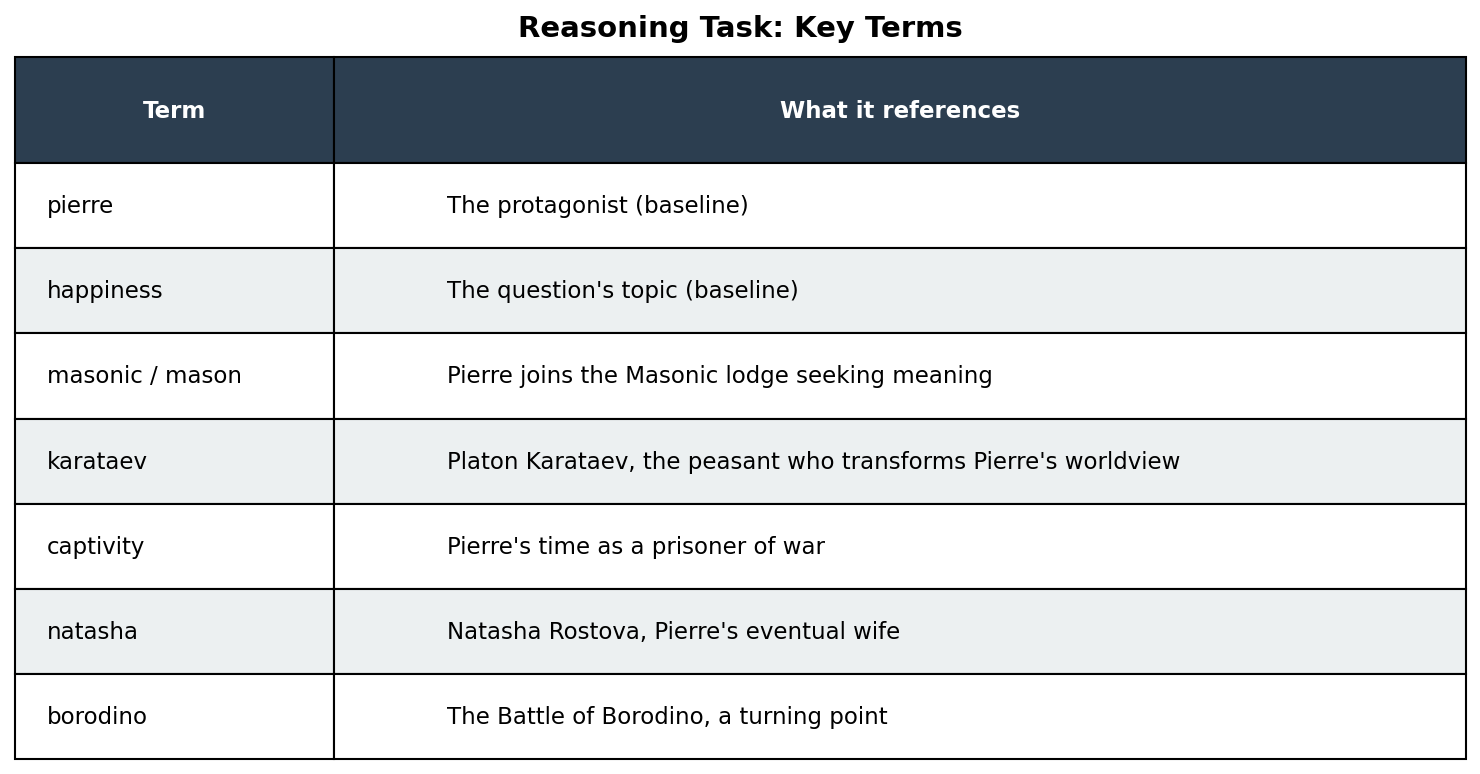
We scored answers by checking whether these terms appeared (substring matching). If an answer mentioned “Karataev,” we inferred the model had successfully found and referenced that section of the book. Two terms (pierre, happiness) are essentially baselines since they appear in the question itself. The remaining terms test whether the model found the relevant plot points.
Pass threshold: 4/8 terms (finding at least half the key plot points indicates the model successfully navigated the document rather than guessing)
Limitations: This approach rewards finding the right sections and using exact terminology. A model that described “the peasant who changed his worldview” without naming Karataev would receive no credit. However, automated scoring enabled consistent evaluation across 30 runs.
Aggregation Task
Corpus: Mega Corpus (2.2M tokens across 6 novels)
Question: “What is the final fate of the protagonist in each of the 6 books?”
What we’re measuring: Can the model systematically explore multiple documents, identify the protagonist of each, and correctly describe their ending?
Scoring approach: Each book scored 1 point if the answer correctly identified both the protagonist and their fate. For example: Pip in Great Expectations ends up reunited with Estella (or alone, depending on the edition). Scoring was binary per book: partial credit (correct protagonist, wrong fate) was not awarded.
Pass threshold: 3/6 books correct (correctly covering at least half the corpus indicates systematic exploration rather than partial success on one or two books)
3. Results
The Variance Problem
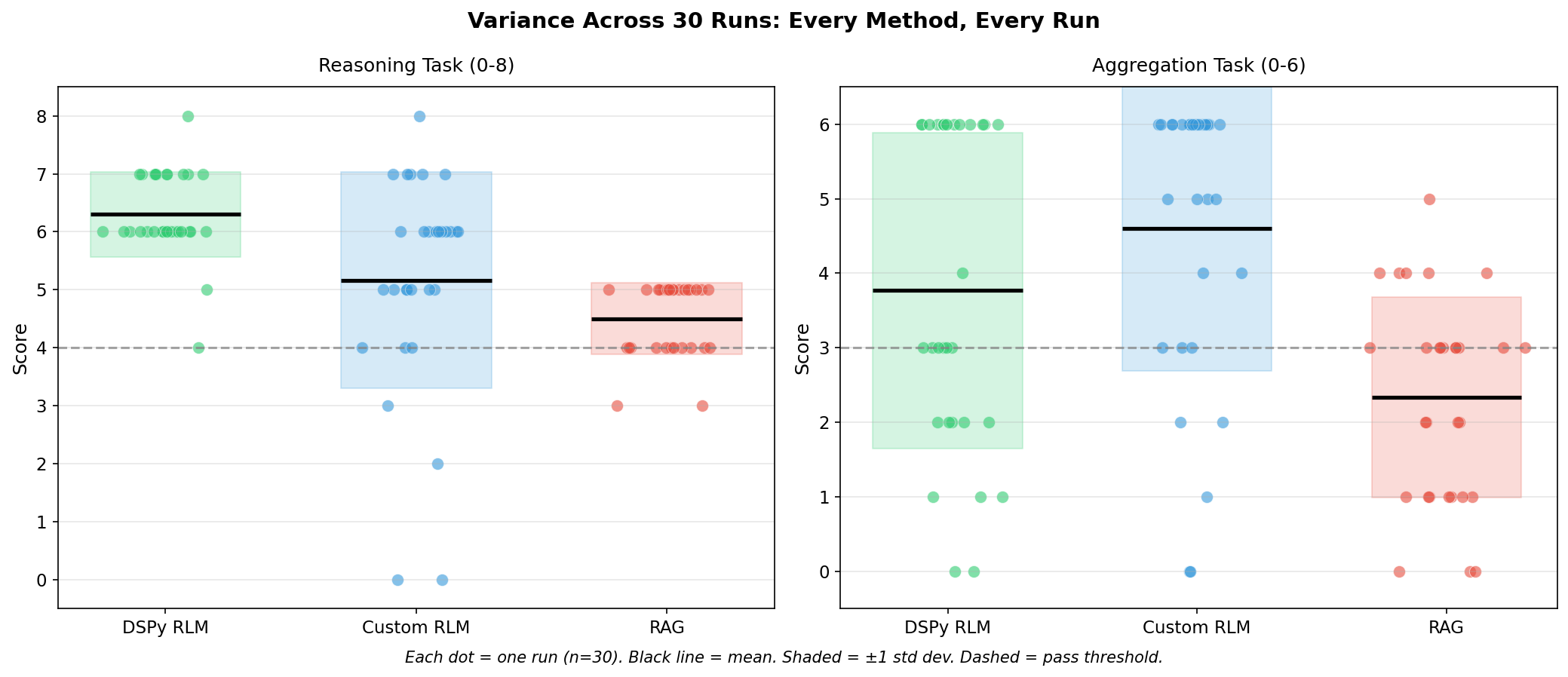
This is the central finding of our research. Identical inputs, identical model, dramatically different outputs. Each dot in the chart above represents one run. The spread tells the story.


What this means: If you ran RLM once on the aggregation task and got 0/6, you might conclude “RLM doesn’t work.” If you got 6/6, you might conclude “RLM is perfect.” Both conclusions would be wrong.
Failure rates tell the deployment story. For aggregation tasks, the probability of near-complete failure (score ≤ 1) was:
Custom RLM: 10% of runs
DSPy RLM: 17% of runs
RAG: 33% of runs
These failure rates matter more than mean scores for production systems. A method with high mean but 17% catastrophic failure rate may be unacceptable for critical applications.
Are the differences statistically significant? With n=30, we can compute 95% confidence intervals:
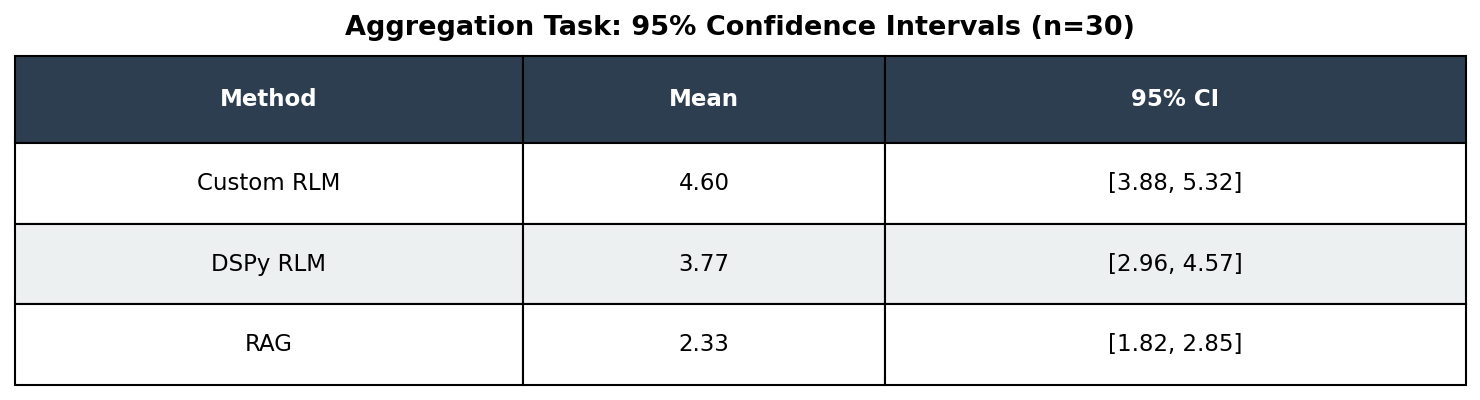
The CIs for Custom RLM and DSPy RLM overlap. A t-test confirms the difference is not statistically significant (p=0.12). While Custom RLM shows a higher mean, the difference could be due to chance. RAG’s lower performance, however, is statistically significant compared to both RLM variants.
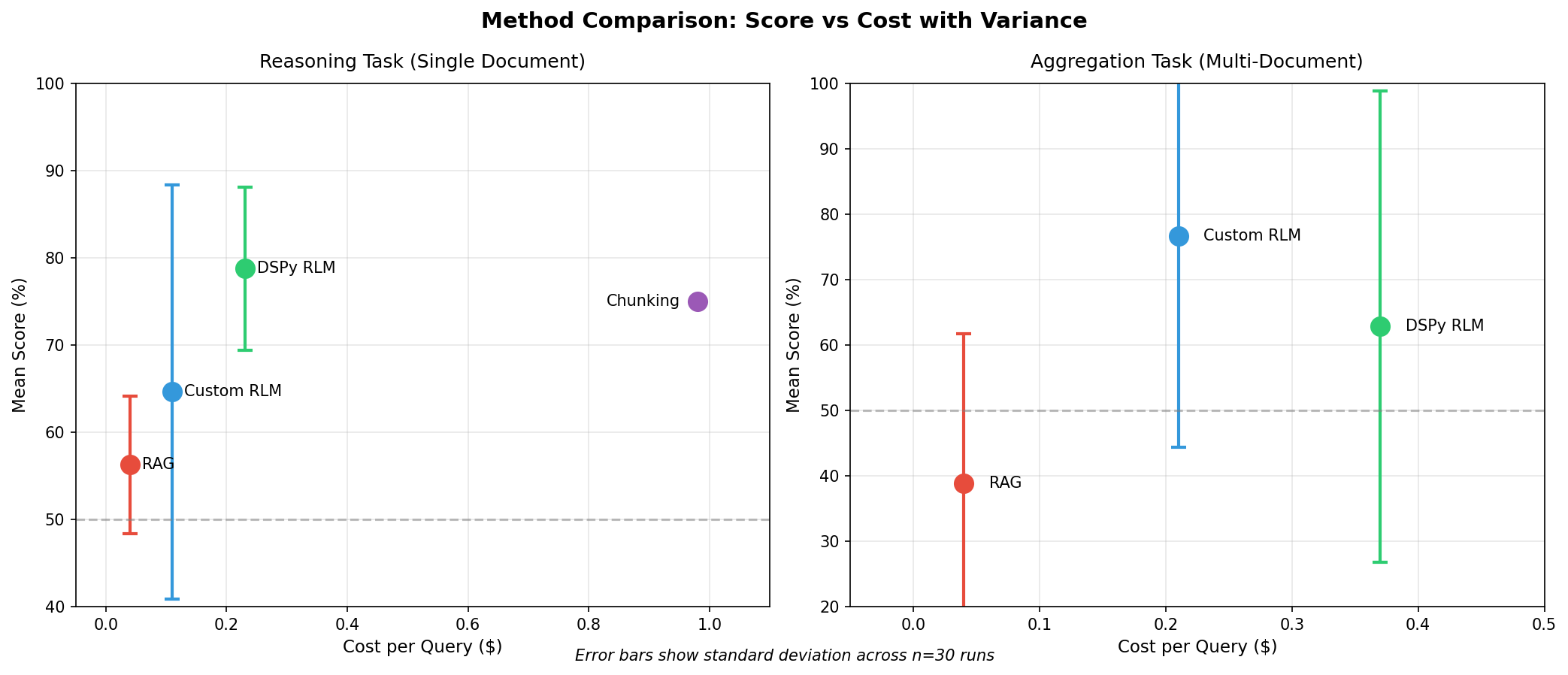
Reasoning Task Results
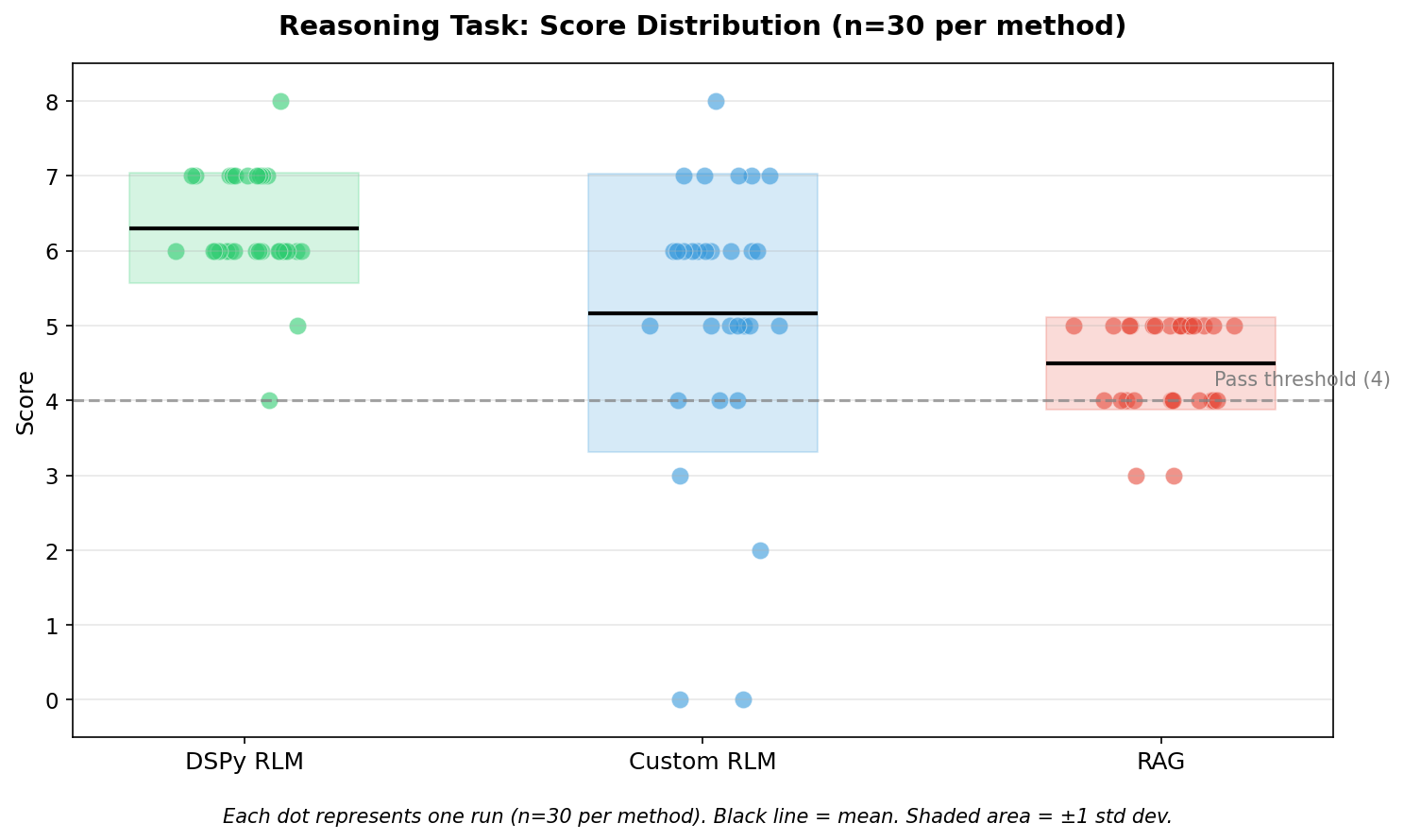
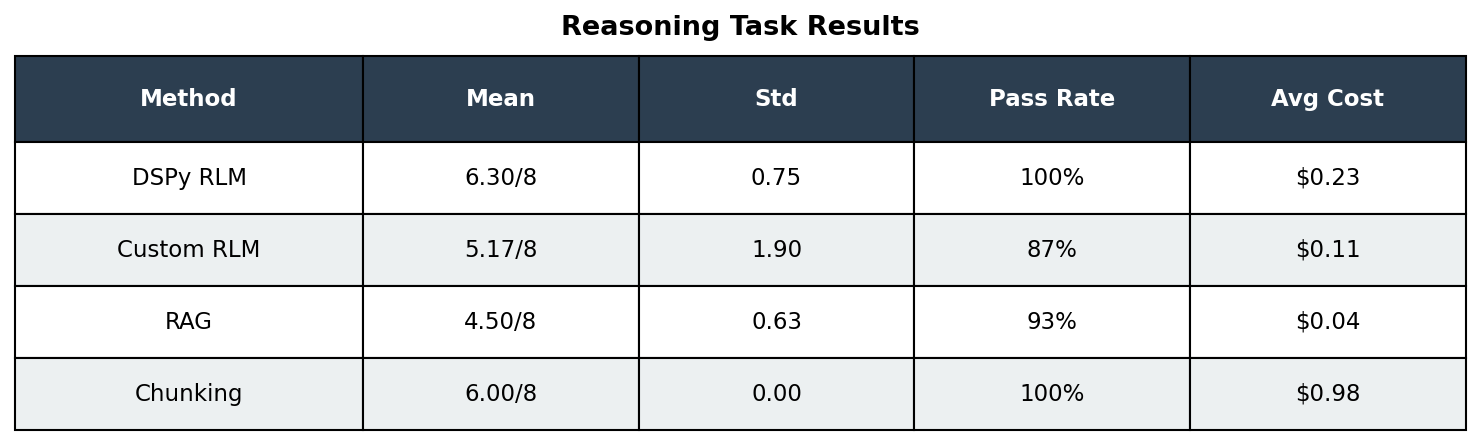
Key observations:
DSPy RLM achieved highest mean score (6.30) with moderate variance
Chunking is perfectly consistent but 4-9x more expensive
Custom RLM has high variance (scores ranged 0-8)
RAG is cheap and consistent but lower accuracy
Aggregation Task Results
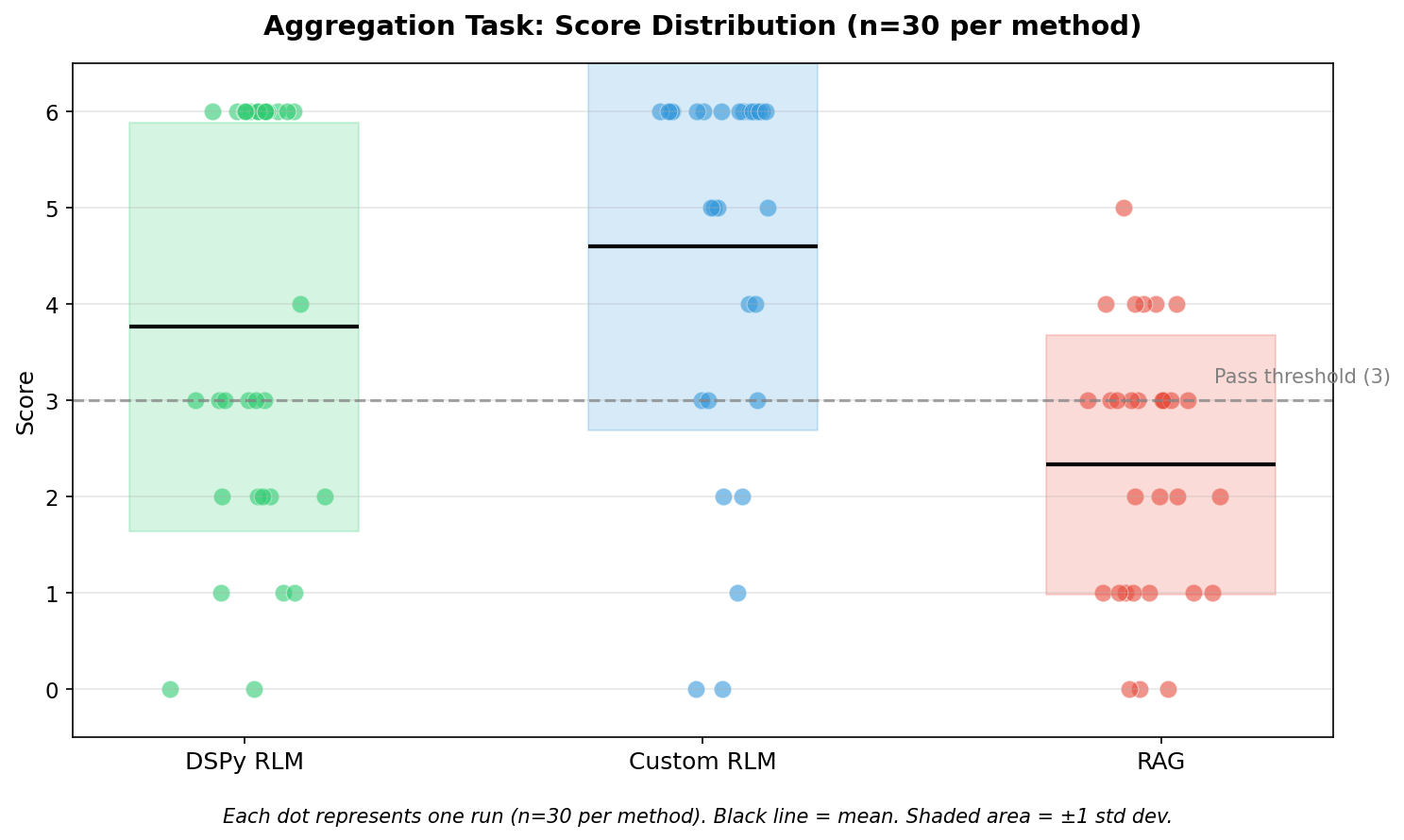
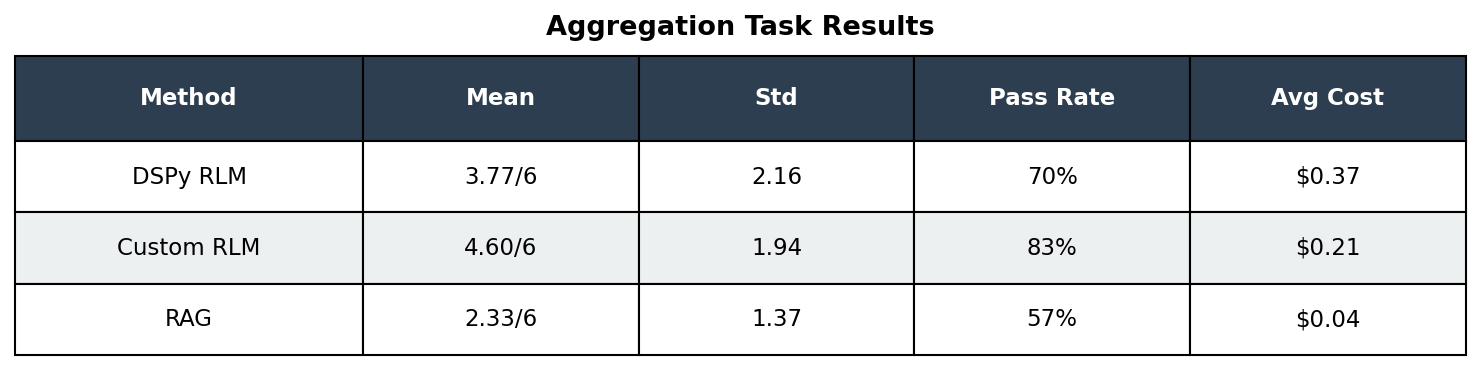
Key observations:
Aggregation shows higher variance than reasoning for all methods
Custom RLM outperformed DSPy RLM on mean score (4.60 vs 3.77)
RAG struggled with multi-document aggregation (33% failure rate). Unlike semantic similarity tasks, aggregation requires systematic coverage with correct book-to-protagonist mapping. RAG’s top-k retrieval pulls the most semantically similar chunks, which may cluster around 2-3 books rather than sampling each of the 6 systematically. This explains RAG’s counterintuitively high failure rate despite its reputation for consistency.
Both RLM variants showed full-range variance (0 to 6)
Model Selection Effect
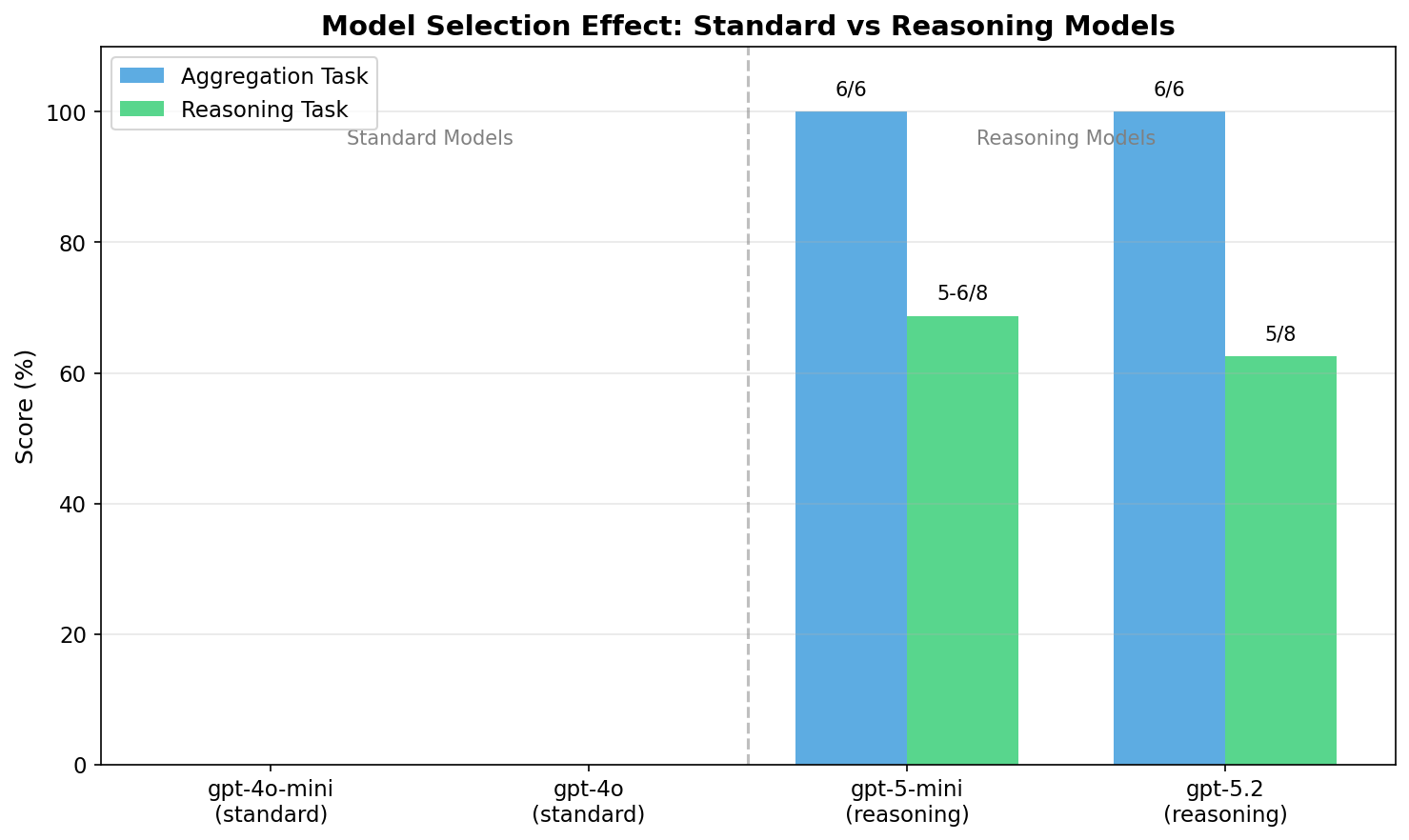
A striking finding: model capability determines RLM viability.
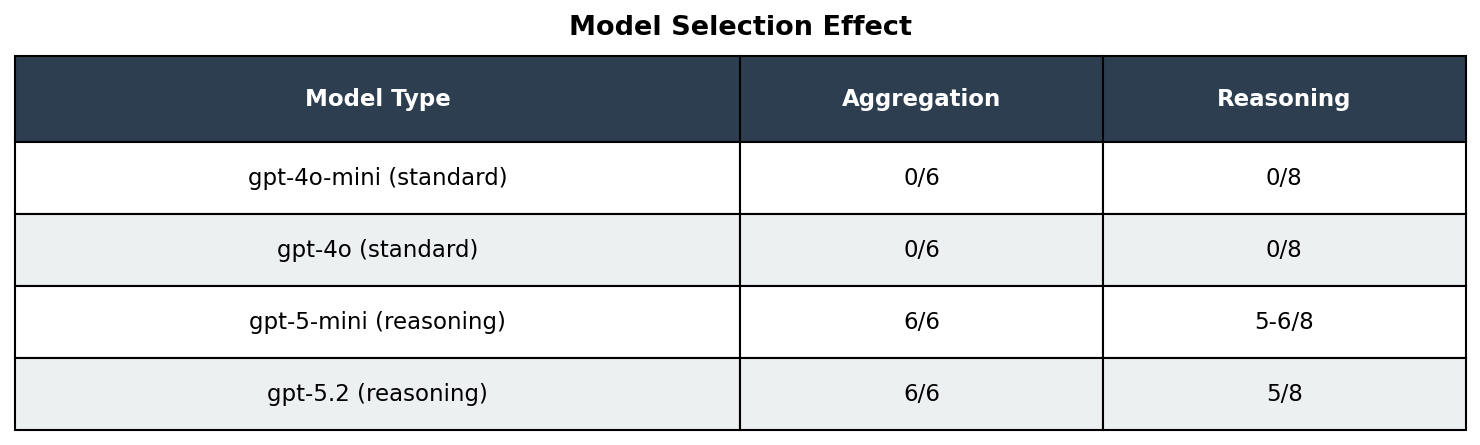
Why reasoning models succeed: They can plan a systematic exploration strategy before executing. Standard models dive deep into the first interesting thread and exhaust their iteration budget.
Cost Analysis
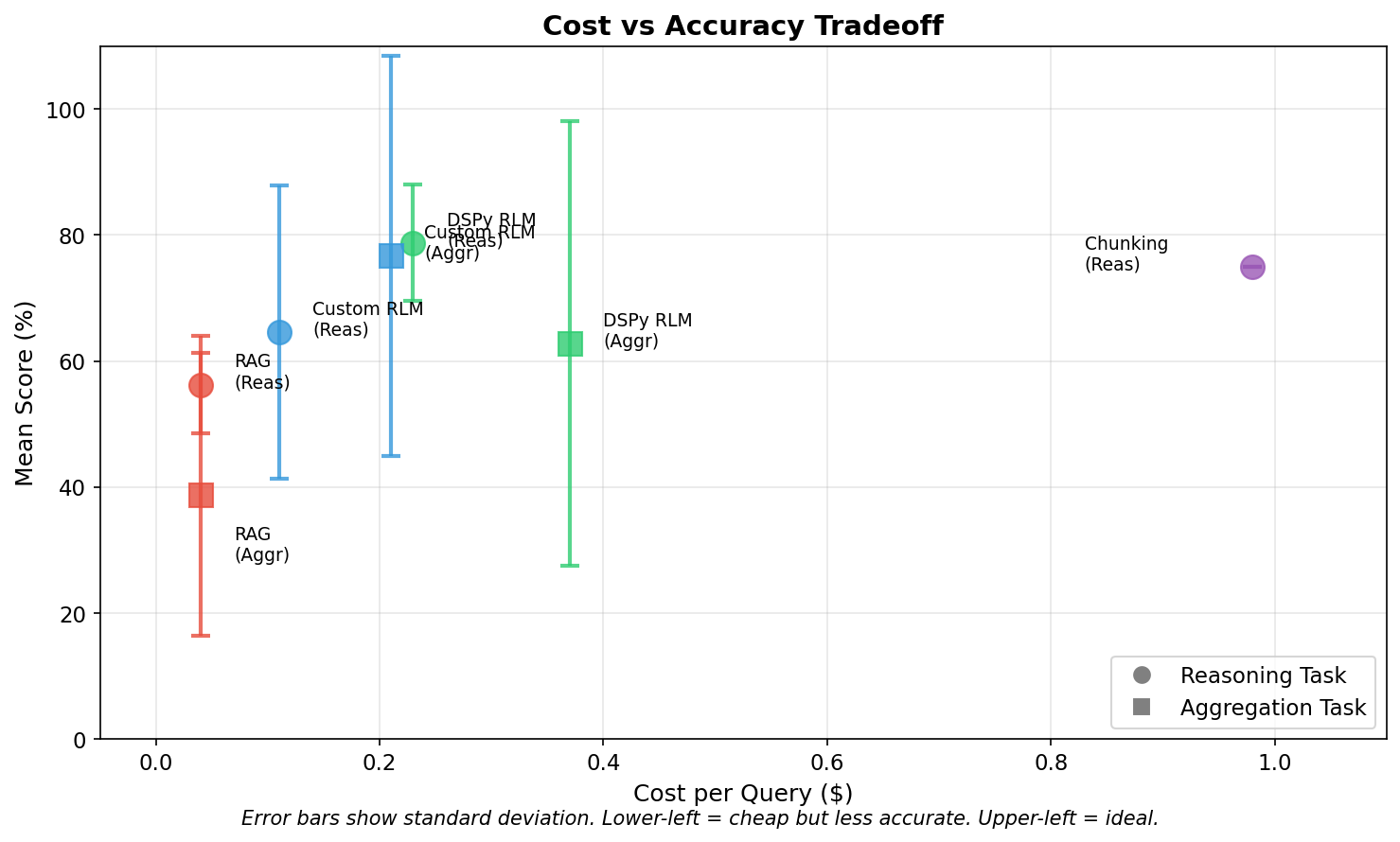
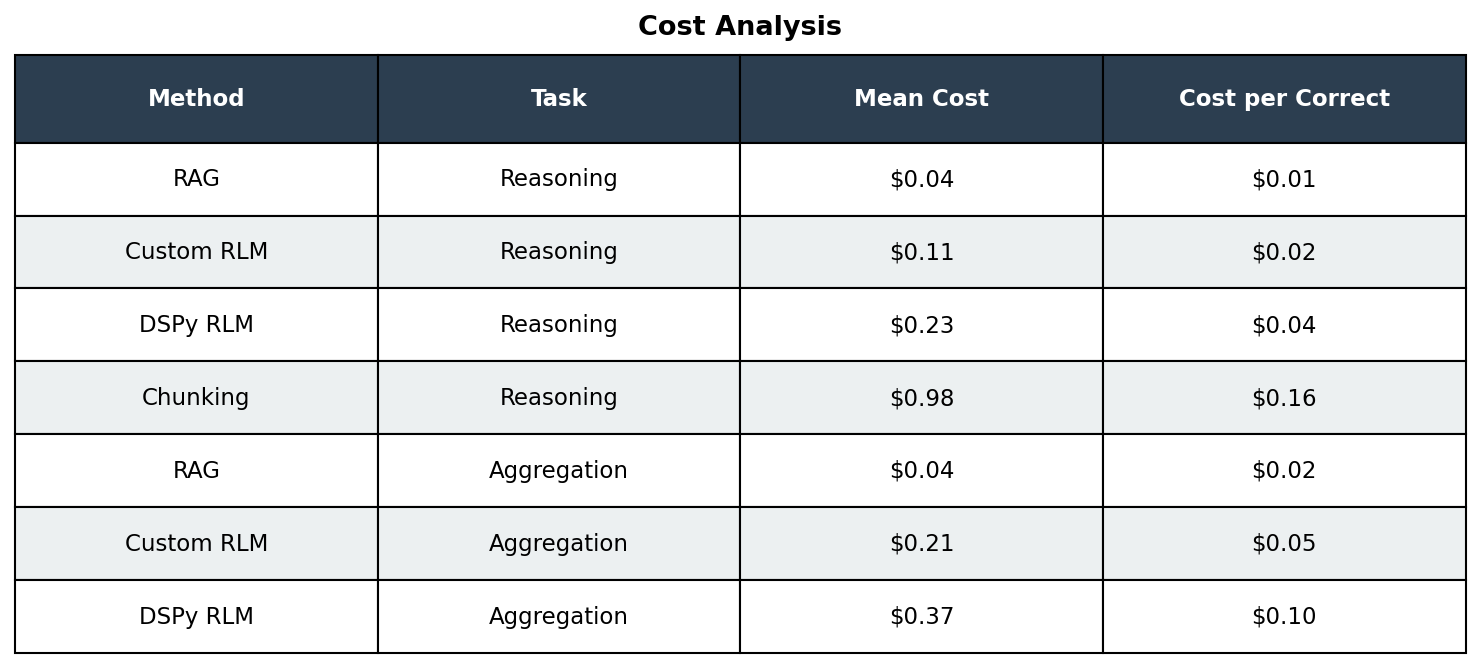
Total variance testing cost: ~$28 for 120 RLM runs
The Retry Strategy: Best-of-3
If variance is unavoidable, can we mitigate it by running multiple times? We simulated a best-of-3 strategy using our existing 30 runs (taking the max score from each group of 3):
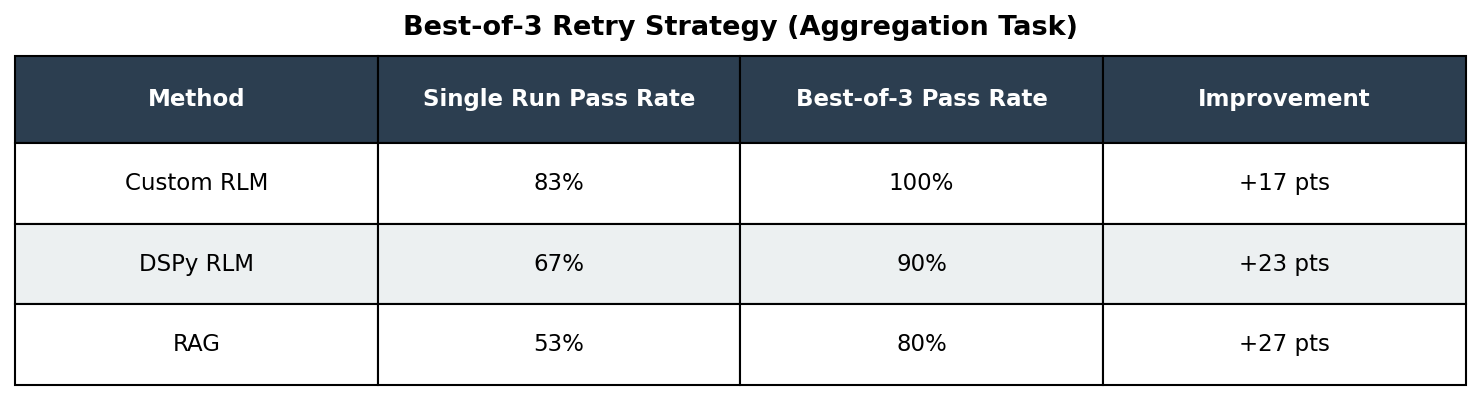
The practical takeaway: Running Custom RLM three times and taking the best result achieves 100% pass rate in our sample on aggregation at ~3× the cost of a single run. This transforms an unreliable method into a deployable one.
4. Discussion
Why Variance Matters
We treat mean score as a measure of capability and failure probability as a measure of reliability. Both matter for deployment decisions, but they answer different questions.
The distributions we observed are heavy-tailed, with occasional catastrophic failures even when mean performance is high. This is why variance matters so much for agentic systems.
Single-run benchmarks are standard practice in AI research. Our findings suggest this practice may systematically mislead:
Cherry-picking risk: Researchers (consciously or not) may report favorable runs
Reproducibility crisis: Others cannot replicate “good” results
Deployment surprise: Production systems encounter the full variance distribution
Recommendation: Report mean and standard deviation from multiple runs, especially for agentic/iterative systems like RLM.
When to Use Each Method
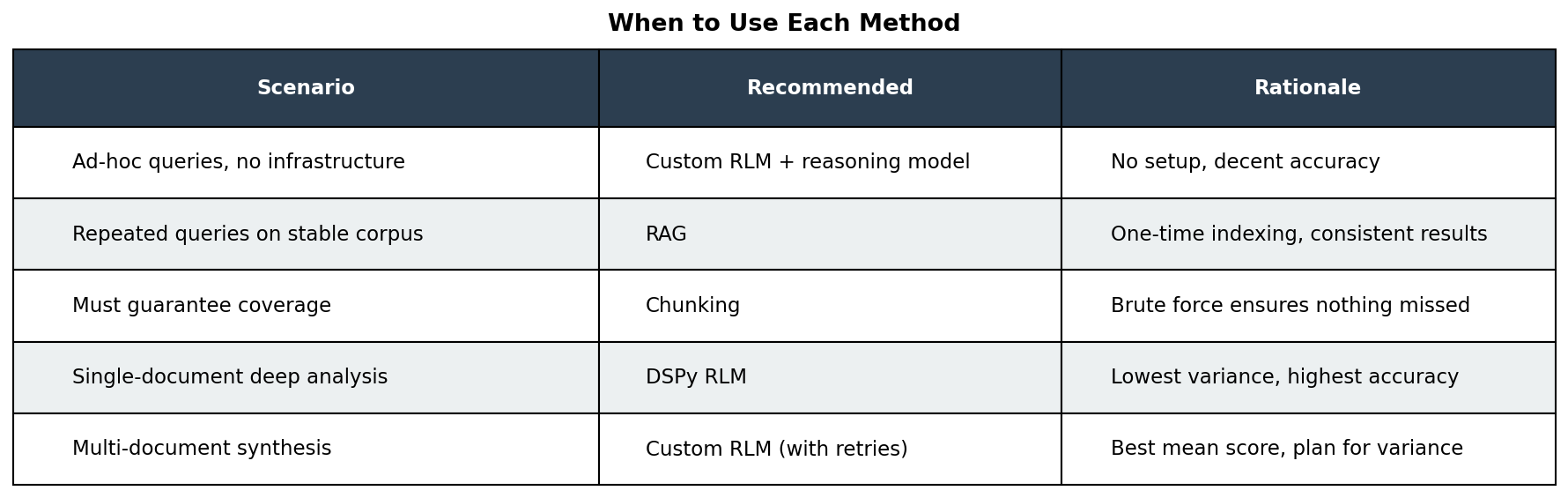
The Reasoning Model Requirement
RLM’s effectiveness depends critically on model capability:
Standard models (gpt-4o, gpt-4o-mini): Cannot execute systematic exploration strategies. Get “stuck” in local optima.
Reasoning models (gpt-5-mini, gpt-5.2): Plan before acting. Enumerate documents before diving deep.
Practical implication: Do not use RLM with standard models for complex tasks. The cost savings are not worth the reliability loss.
Library vs Custom Implementation
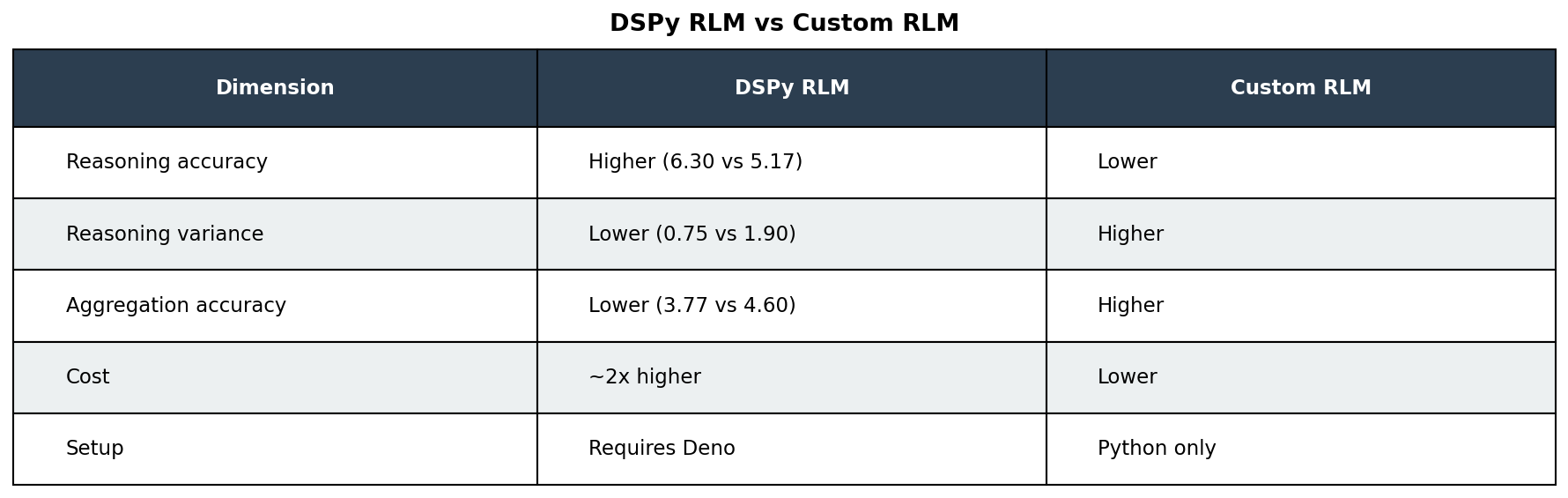
We compared two approaches: using DSPy’s built-in RLM module versus building a custom implementation following the paper’s methodology.
Why did our custom implementation outperform on aggregation? Our custom prompts explicitly guided the model to sample the beginning of documents first, understand naming conventions, and systematically enumerate all books before diving deep. DSPy’s generic RLM module lacks this task-specific guidance, which may explain why it excelled at depth (single-document reasoning) but struggled with breadth (multi-document coverage).
Recommendation: For single-document reasoning where consistency matters, use an existing library like DSPy’s RLM module. For multi-document synthesis where mean accuracy matters more than run-to-run variance, building a custom implementation with task-specific prompts may yield better results.
5. Limitations
Literary corpus only: Results may differ on technical, legal, or scientific documents
Training data contamination: These classic novels are almost certainly in the training data of frontier models. We cannot determine how much the models “remember” versus genuinely discover through RLM exploration. Results on proprietary or novel documents may differ.
Single model family: All tests used OpenAI models; other providers may show different patterns
English only: Non-English documents not tested
Scoring subjectivity: Key-term matching is imperfect for nuanced questions
6. Conclusion
RLM delivers on its promise of efficient long-document processing, but with important caveats:
Variance is real and significant.
Plan for it. Run multiple times for important queries.
Model selection is critical.
Reasoning models are not optional; they’re required for reliable RLM.
Task type matters.
RLM excels at single-document reasoning; struggles more with multi-document aggregation.
Tradeoffs are real.
Lower token costs come with higher variance. Chunking’s brute-force consistency has value.
For practitioners: If you need consistent results on stable corpora, invest in RAG infrastructure. If you need flexible ad-hoc queries without setup, use RLM with a reasoning model, but run it multiple times and aggregate results.
For researchers: Report variance. Single-run benchmarks on agentic systems may be systematically misleading.
Appendix: Raw Data
All n=30 results available in CSV format upon request.
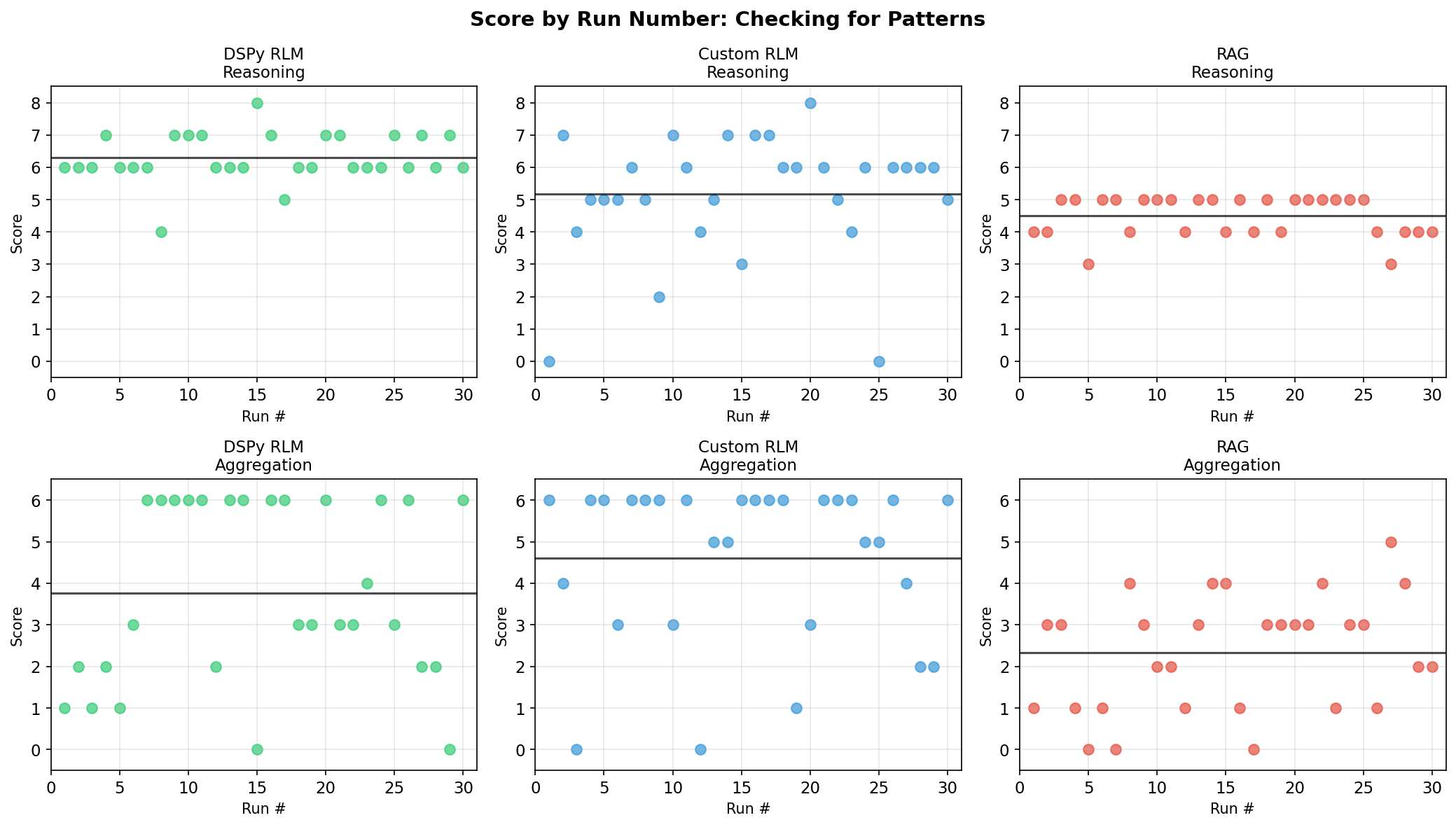
What this chart shows: Each panel plots score (y-axis) against run number (x-axis) for one method/task combination. The black horizontal line is the mean. Notice there’s no pattern: run #1 isn’t better or worse than run #30. The variance is truly random, not a warmup effect or degradation over time. This confirms the variance we observed is inherent to the method, not an artifact of our testing procedure.
Research conducted February 2026. Code and data available upon request.