
Multi-Agent Account Planning That Learns Across Deals
Fifteen agents across five phases, with a decision-records harness that compounds insight. A working guide to multi-agent orchestration on Claude Managed Agents.

Intro
Anthropic shipped multi-agent orchestration in Managed Agents on May 6th. An agent can be configured as a coordinator with a roster of other agents it can delegate to, and the platform handles fan-out, child-thread lifecycle, parallel execution, and per-thread observability.
Anthropic also shipped a management console. Every agent, session, child thread, and memory write is browsable, with full transcripts, tool calls, and version history inspectable on click. That console shaped how I built the system, because the logging I would have written myself was already there.
The use case I built is account planning in B2B SaaS sales. The vendor is a fictional company, Yardstick AI, selling an AI evaluation platform. The prospect is Vercel, a real company with a public footprint rich enough to give the agents something genuine to research.
The system has fifteen agents organized into a five-phase pre-meeting orchestration plus a post-meeting debrief loop. The pre-meeting flow has two genuine decision steps where the coordinator chooses what runs next based on what just came back, not a fixed sequence.
It uses MCP servers (Notion, Slack), the Anthropic vault for credentials, two memory stores (a playbook and a decision-records corpus), custom HTTP tools for a mock CRM and enrichment service, and the built-in web search and fetch tools.
Most of the system’s analytical work happens in the layer of decision records that the agents read from and write into. The records get captured two ways.
Implicitly, the system infers decisions from CRM record changes, activity logs, and other signals that move without anyone narrating them.
Explicitly, after each meeting, the system uses the full account plan plus the surrounding events (calendar entries, CRM stage moves, recent activity) to compose a curated set of questions for the rep. The questions are shaped by what the system already knows about the account, so they target the specific decisions most likely to produce useful data instead of asking generic “how did it go” prompts.
Whichever way a record gets created, it lives in a shared memory store that the next account’s run can retrieve and reason from. That is the difference between a system that gives you one prep brief and a system that gets better at giving you prep briefs as it accumulates evidence.
This post documents what I built, what worked, what did not, and what the costs and constraints actually look like once you push past the basic demo.
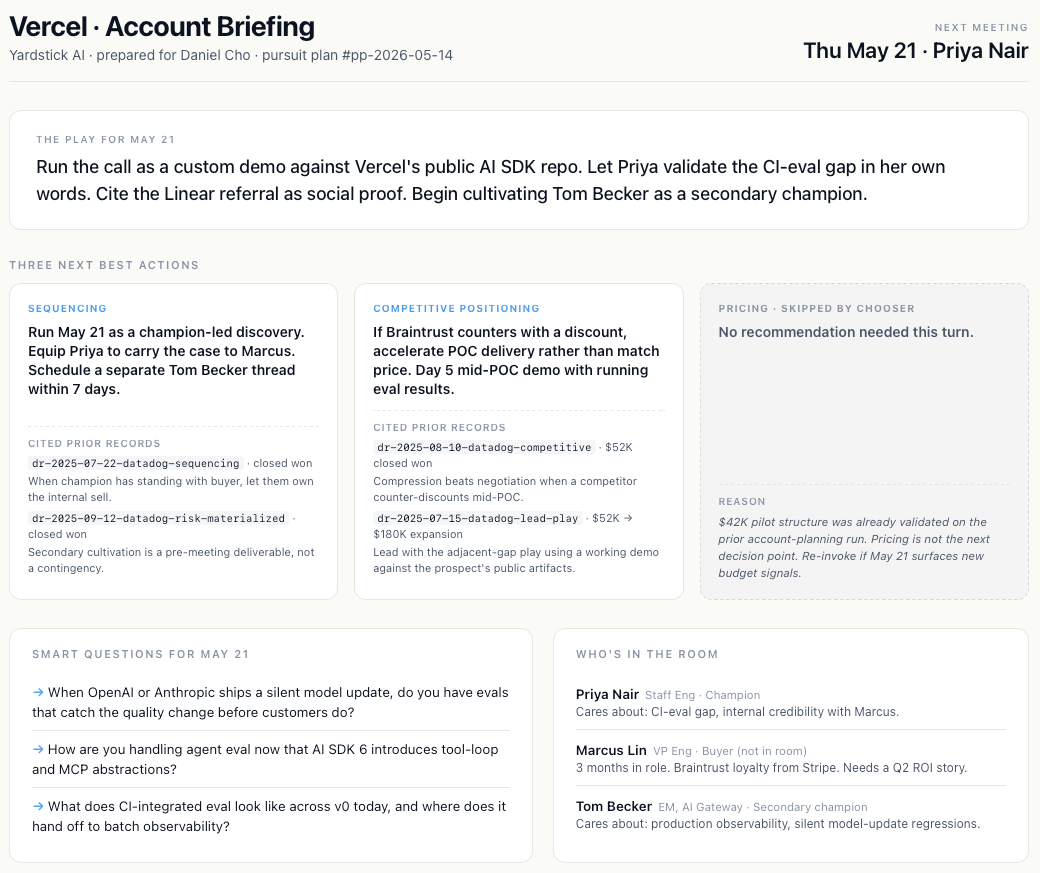
Below is a capture of the final product:
What you’ll learn
This post walks through what I learned building a multi-agent system in Anthropic Managed Agents. The official documentation covers the basics. This post covers what comes after that: how the primitive holds up when you push it against a real, multi-source, multi-phase problem. By the end you should have a clearer sense of when this architecture is worth using and what it takes to make it work.
Concretely:
What multi-agent really is inside the platform. The shape of the architecture, where the limits actually sit, and what the docs do not yet spell out.
How the system remembers things during a run versus across runs. Two different kinds of memory live side by side, and a real system has to be deliberate about where each finding goes.
Why use multi-agent over a workflow. When the coordinator’s runtime decisions justify the complexity, and when they do not.
How decision records make the system compound. A structured corpus of recommendations and their resulting decisions turns each run into evidence the next run can use.
The agent harness. Everything you build around the platform primitives to make the system work for your use case: the MCP servers you connect, the record schemas your corpus enforces, the system prompts that define each agent’s job, the routing logic the coordinator follows, the briefings it hands to each agent.
Async surfaces via MCP. How Slack becomes part of the system through MCP, so the rep can capture decisions in-place after a meeting without a custom bot.
The distillation problem. Why the system’s raw output is not usable on its own, and what has to happen to make it useful to a human in thirty minutes.
Cost and observability. Per-thread spend, total cost for a full run, and what the Managed Agents console gives you for free.
Honest findings. Pitfalls a builder should expect to hit on their first run.
When this is the right tool, and when it isn’t. What kinds of problems multi-agent orchestration fits, and what kinds belong with a simpler architecture.
Section 1: The work of account planning
An account executive working a B2B SaaS deal is doing one job continuously and several others on top of it. The continuous job is synthesis. At any moment in a pursuit, an AE is holding context across half a dozen sources: their own notes from past calls, the CRM record with its stages and activity log, public signals (product launches, hires, press), conference encounters and hallway intel, backchannel from people who used to work there, win and loss patterns from similar accounts, and their own company’s internal playbook. None of these sources are formatted alike, refresh on the same cadence, or answer the same questions week to week.
The job sits on top of a rhythm of meetings. Before each meeting, the rep does pre-meeting prep. After each meeting, the rep does post-meeting capture. Between meetings, follow-up. The cadence is continuous, across fifteen to thirty active accounts at any given time. Even the most disciplined AE admits the synthesis happens in their head more than on paper, and the capture happens only when there is slack to capture.
What makes this work a candidate for multi-agent orchestration is the shape of the synthesis problem: the sources decompose naturally by role. Reading internal Notion notes, researching the company on the public web, mapping the org chart, and synthesizing all of it against a playbook are four different jobs. Each role wants a different tool surface, and each role’s output is most useful when it is separate from the others until the synthesis step. Running them in parallel saves wall-clock time, but the more interesting property is that each role can be a focused agent with a small system prompt and a tight tool surface, rather than one generalist agent trying to be five things at once.
The 30-minute pre-meeting slice is the moment in this rhythm where multi-agent orchestration is most legible. The rep has a calendar event coming up. They want a brief that consolidates what is knowable from everywhere into something they can read in five minutes, prepare around in twenty, and act on in the meeting itself. That is the moment this post centers on, but the architecture supports the broader cadence around it.
Section 2: What multi-agent in Managed Agents actually is
Most coverage of “agents” uses the term to cover everything from a single Claude call to a fully autonomous AI team that plans its own work. Anthropic’s multi-agent feature is neither extreme. It is a specific pattern with specific constraints, and the constraints are worth knowing before you build against it.
The shape: coordinator with a roster
One agent is the coordinator. Its definition includes a list of other agents it is allowed to delegate to. That list is called the roster. A few specific limits:
The roster can hold up to 20 agents.
The coordinator can call multiple copies of any agent on the roster.
A session can have up to 25 active threads running at once.
Specialists cannot delegate to other specialists. The architecture is flat, not nested (Anthropic’s docs phrase it as “depth > 1 is ignored”).
If you came in expecting agents that delegate to agents that delegate to agents, the spec corrects you on page one. What you get is a flat fan-out from a single coordinator. For most real systems this is the right tradeoff.
Threads: how the system stays organized
A thread is a separate, isolated conversation that belongs to one agent. Each thread has its own history and tools. Threads don’t share anything with each other, even though they all run inside the same session.
Two kinds:
The primary thread is the coordinator’s own thread. It also doubles as the activity feed for the whole session.
A child thread is created when the coordinator delegates to a specialist. The platform copies the session’s tools and credentials onto that thread, and the specialist’s work runs there.
When the coordinator delegates to multiple specialists in the same turn, the child threads run in parallel. The coordinator waits for each reply before deciding what to do next. You don’t write any of the glue code for this. The decision-making that would normally live in a script lives inside the coordinator’s prompt.
Thread lifecycle
A thread moves through three states:
Running: the specialist is actively working.
Idle: the specialist has finished but the thread is still alive. It counts against the 25-thread cap.
Archived: you have told the platform you are done with the thread. The slot is freed.
For most builds, the 25-thread cap is generous enough that you never think about lifecycle. Systems that lean hard on parallel work have to treat archiving as part of the orchestration.
Idle threads stay alive, which enables follow-ups
Because an idle thread is not gone, the coordinator can send a follow-up message to a specialist it called earlier. The specialist keeps its full context from before. That means the architecture supports more than one round of back-and-forth per specialist, not just one-shot delegation. I did not use this in the build, but in retrospect there are several places it would have helped.
Two kinds of memory
The system has two layers of memory that work on different time scales:
Persistent threads keep a specialist’s context alive within a session. The moment the session ends, the threads are gone.
Memory stores persist across sessions. They are objects shared across the whole workspace, mounted onto a session when it starts. Anything written into one stays available to the next run that mounts the same store.
A real multi-agent build needs both.
Designing the split
The design split lives in two questions:
Within a session: which specialists do you keep alive for a follow-up, and which do you fire once and let go?
Across sessions: which findings deserve to be promoted into a memory store, and which can evaporate when the session ends?
The platform gives you the building blocks for both. It does not decide which findings belong where. Get that split wrong and you pay either way:
Throw away thread context too early, and you re-brief the specialist on every follow-up.
Fail to promote findings into a store, and the next session starts cold on everything you already learned.
Our build leans heavily on the cross-session side. Most of the analytical work in this system comes from the decision-records corpus, which is the through-line for the rest of this post.
Section 3: The agent architecture
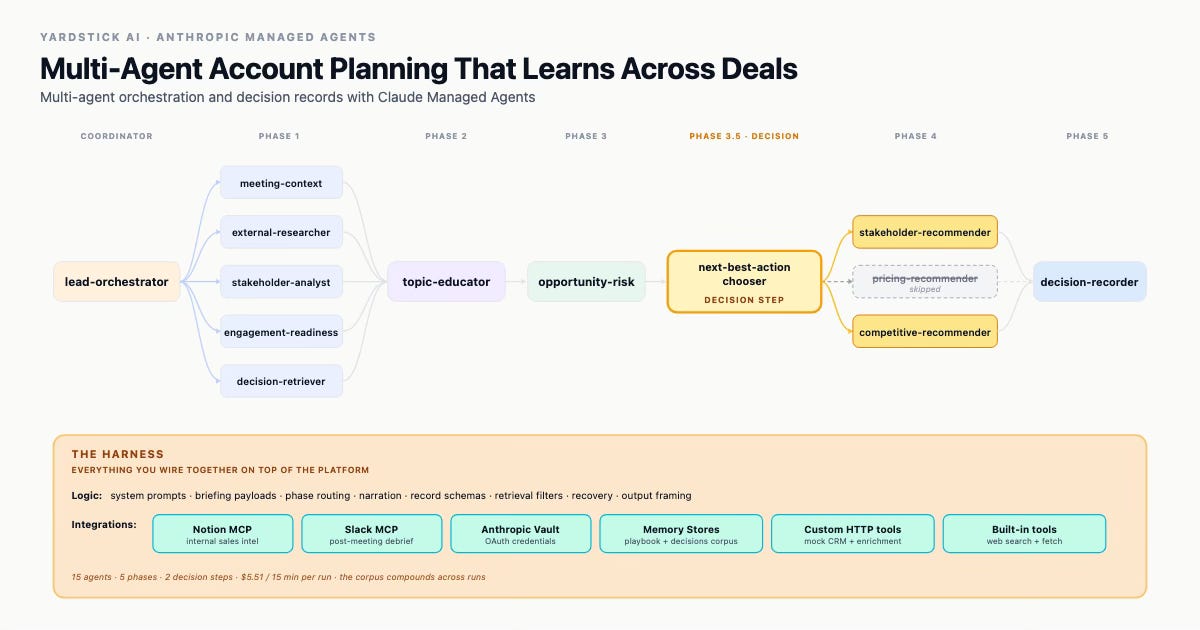
The pre-meeting orchestration uses thirteen agents: one lead orchestrator plus twelve specialists in its roster. The post-meeting debrief loop adds two more agents that sit outside the coordinator entirely. Fifteen across the system.
Pre-meeting work is a tightly scoped synthesis problem that benefits from a coordinator. Post-meeting work is a slower, human-paced loop that does not benefit from coordination at all, just two single-purpose agents that read and write a shared corpus.
The pre-meeting run breaks into five phases, sequential at the coordinator level and parallel within. The coordinator narrates each phase boundary as it runs, which makes its reasoning visible and forces the model into a structured plan rather than letting it improvise.
Phase 1: gather context and pull prior records
Five specialists fan out concurrently:
meeting-context: reads internal Notion notes through Notion MCP.
external-researcher: pulls public signals from the web.
stakeholder-analyst: maps decision-makers via a mock enrichment service.
engagement-readiness: hits a mock CRM for outreach history.
decision-retriever: runs against the shared decision-records corpus and pulls prior decision records from past accounts that match the current account’s shape (by attribute overlap: industry, competitor present, champion profile, procurement complexity, and so on).
Phase 2: conditional topic education
The coordinator inspects what Phase 1 surfaced and picks two to four technical topics worth briefing the rep on before the meeting. For the Vercel run, those topics included cross-provider eval methodology, agent eval, AI observability, and eval-driven CI.
topic-educator: runs against the curated topic list and returns a primer per topic, each ending with smart questions the rep can ask in the room.
If the account does not warrant it, the coordinator skips Phase 2 entirely.
Phase 3: synthesis
opportunity-risk: receives everything Phase 1 and Phase 2 produced, mounts the read-only Yardstick playbook from a memory store, reads the prior decision records the retriever pulled in Phase 1, and writes the structured pursuit plan. The plan covers ICP fit, buying triggers, stakeholder map and sequencing, first-meeting hypothesis, recommended plays, and disqualifiers.
Phase 3.5: next-best-action selection
After the synthesis is in, the coordinator does not jump straight to recording. It asks one more specialist, the chooser, to decide which concrete recommendations are warranted for this specific account.
next-best-action-chooser: reads the synthesis plus the prior decision records the retriever pulled in Phase 1, decides which of three specialized recommenders to invoke, and writes a focused brief for each. The chooser can also skip a recommender, with a reason. A different account with different synthesis and different prior records produces a different plan.
The three recommenders available to the chooser:
stakeholder-recommender: sequencing or lead-play.
pricing-recommender: pricing strategy.
competitive-recommender: competitive positioning or risk mitigation.
Phase 4: parallel recommendation generation
The coordinator dispatches whichever recommenders the chooser named. They run in parallel. Each one produces a single Recommendation Record (RR) as a markdown draft with strict YAML frontmatter and a cited_records block listing the prior decision records whose outcomes informed this recommendation. The recommenders hand drafts back to the coordinator; they do not write to the corpus themselves.
Phase 5: decision recording
decision-recorder: receives the RR drafts, validates each one against the schema, checks every cited prior decision record exists in the corpus, writes the validated records to
/mnt/memory/yardstick-decisions/, and updates the corpus index.
Splitting content generation (the recommenders) from persistence (the recorder) keeps each role focused.
Post-meeting: the debrief loop
That accounts for the thirteen pre-meeting agents. The remaining two run on the post-meeting side:
debrief-asker: reads the next-best-action RRs the pre-meeting run produced, picks the open questions still unresolved, formats them as a curated set, and posts them into a Slack channel through the Slack MCP server. The rep replies in the thread on their own time.
debrief-synthesizer: once there are replies, reads the Slack thread, parses the rep’s answers, and writes Decision Records into the corpus with the
linked_rrfield pointing back to the originating RRs.
Neither sits in the coordinator’s roster because neither runs synchronously with the pre-meeting flow. They run on a human-paced timescale, possibly hours or days later. Coordinating them through the same session would require keeping a session open across days or weeks, which the platform does not support. The cleaner shape is two single-purpose agents that share the corpus as their interaction substrate.
Section 4: What the platform gives you for observability
Most multi-agent demos require you to build your own logging before you can debug them. Managed Agents takes the opposite stance. Anthropic ships a management console that turns every agent, every session, every child thread, and every memory write into a click-through artifact you can inspect without writing any instrumentation.
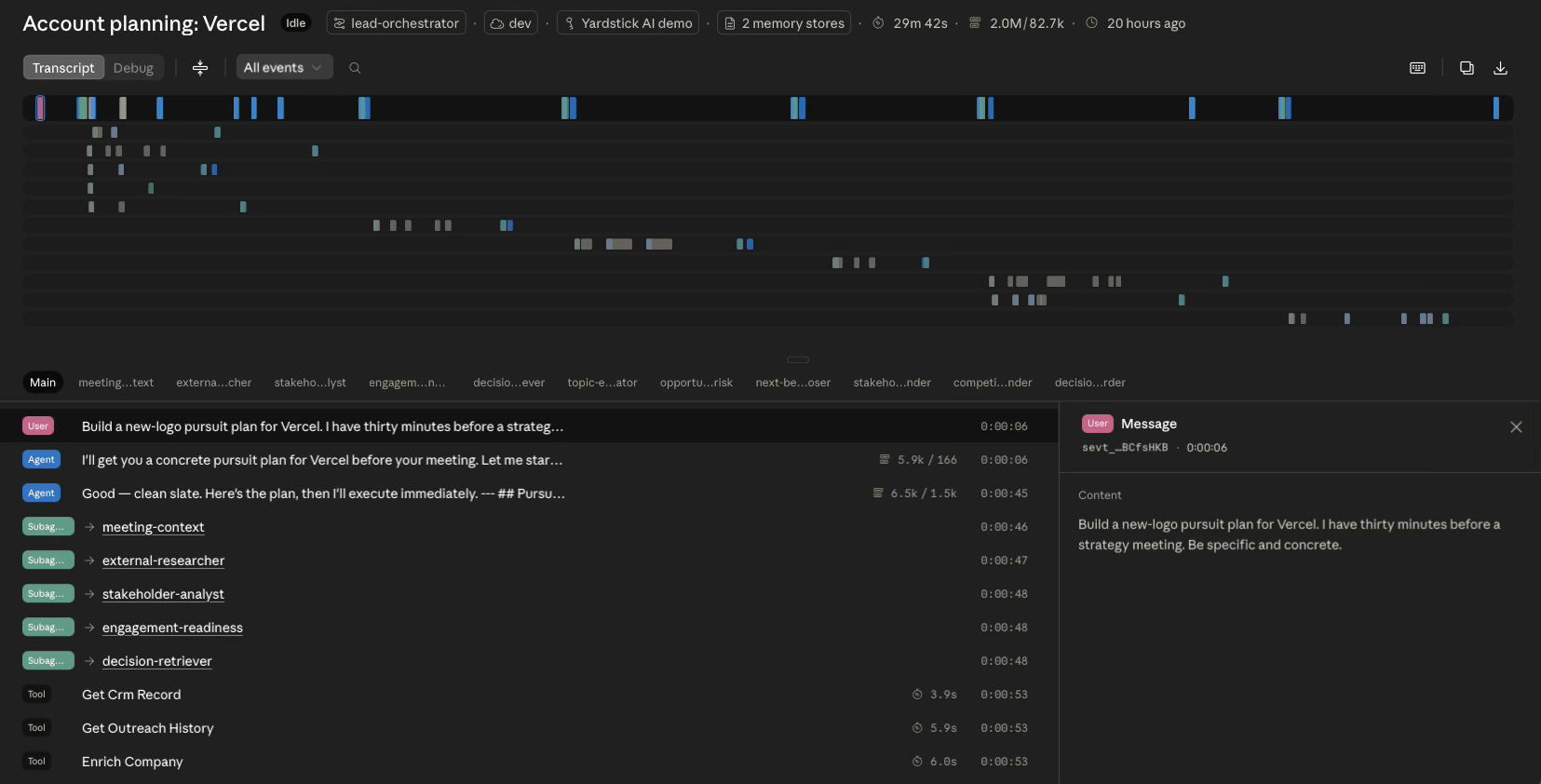
The console is structured around the platform’s primary objects. The Agents tab lists every agent you have created with its system prompt, declared MCP servers, custom tools, and toolsets all inspectable on click. Versioning is built in. The Sessions tab shows every session with the coordinator’s primary thread and every child thread enumerated, status per thread, full transcripts including the model’s reasoning content, and every tool call shown inline with its inputs and outputs. The Memory Stores tab tracks version history so any write to the decision-records corpus is auditable end to end.
At runtime, the same data is available programmatically through the events API. The session-level stream gives you a condensed feed across the whole session. Per-thread streams give you raw event sequences for any specialist. The three events that matter for fan-out observability are session.thread_created, agent.thread_message_received, and session.thread_status_idle. Stringing those together gives you the fan-out timeline of the whole run without writing a single instrumentation line.
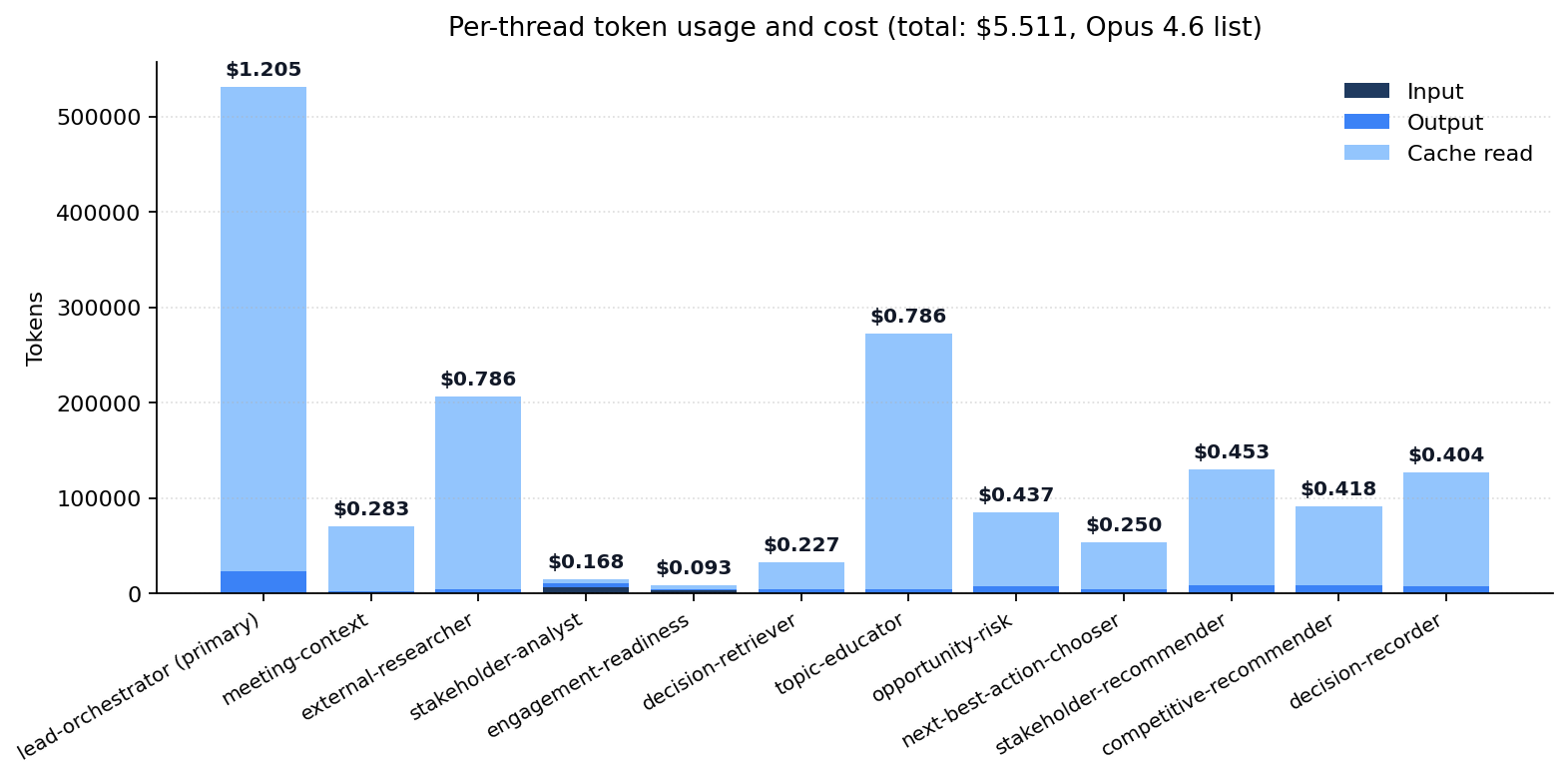
Cost data is similarly structured. Every event carries usage data scoped to the thread that produced it. The full Vercel run cost $5.51 across the pre-meeting orchestration. Thirteen agents sit in the roster, but the conditional dispatch in Phase 3.5 chose to invoke only eleven of them for this account (one recommender was skipped on substance).
The cost shape is what the chart makes obvious. The lead-orchestrator dominates at $1.21, because it is the one thread that accumulates context across every phase. The two heaviest specialists are external-researcher and topic-educator at about $0.79 each, both driven by web-tool use rather than cumulative context. The Phase 4 recommenders, the Phase 3 synthesis, and the Phase 5 decision-recorder cluster in the $0.40 to $0.45 range, each receiving the cumulative context from prior phases plus the prior decision records the retriever pulled in Phase 1. The remaining Phase 1 specialists sit at $0.28 or below. Wall-clock was about fifteen minutes from prompt to final answer.
Section 5: What multi-agent gives you that a workflow can’t
Multi-agent orchestration is only worth using when the coordinator makes a real decision between phases. If your design fans out, waits for results, and synthesizes them, you have built parallel API calls dressed up as a multi-agent system. The platform’s complexity (extra threads, longer latency, harder debugging) buys you nothing a sequential workflow couldn’t already do.
The thing that justifies the complexity is the moment the coordinator pauses, looks at what the previous phase produced, and decides what should happen next. That decision is the part a workflow cannot replicate, because a workflow has to know in advance what it is going to do.
In our build, there are two such decision steps.
The first lives between Phase 1 and Phase 2. Phase 1 fans out five specialists to read the account from five angles. The coordinator collects their output, pauses, and picks two to four topics worth briefing the rep on before the meeting. For Vercel, the coordinator chose cross-provider eval methodology, agent eval, AI observability, and eval-driven CI. None of those topics are defined anywhere in advance. They are picked from what Phase 1 surfaced about this specific account. A different account would produce a different list, or no list at all, in which case the coordinator skips Phase 2 entirely.
The second lives between Phase 3 and Phase 4. After opportunity-risk produces the synthesis, the coordinator dispatches the next-best-action-chooser, which reads the synthesis plus the prior decision records the retriever pulled in Phase 1 and decides which of three specialized recommenders to invoke: stakeholder, pricing, or competitive. On the Vercel run the chooser invoked stakeholder-recommender and competitive-recommender, and skipped pricing-recommender with the reason that the $42K pilot structure was already validated. Skipping with a substantive reason is what separates a real decision from a conditional that always fires.
The coordinator narrates each decision as it happens, which makes the reasoning visible:
Phase 1 specialists are back. External-researcher found public Braintrust endorsement at Vercel that the internal Notion notes treated as a stalling competitor. Phase 2 launched. Topic-educator is building primers on cross-provider eval, agent eval, AI observability, and eval-driven CI based on what surfaced.
Phase 3.5 complete. Invoking stakeholder-recommender (sequencing) for the May 21 call sequencing and Tom-Becker cultivation. Invoking competitive-recommender (competitive_positioning) for the Braintrust counter-offer scenario. Skipping pricing-recommender: $42K structure already validated, pricing isn’t the next decision point.
That kind of reasoning is what tells you the coordinator is actually orchestrating rather than executing. A workflow could fan out the same specialists in parallel. It could even hard-code the topic-educator and recommender steps. What a workflow cannot do is pick which topics to brief on this turn for this account, or which recommenders are warranted given what the synthesis just surfaced. Those decisions require a model with the full context loaded, which is exactly what the coordinator is.
Section 6: Decision records: the layer that compounds
A memory store by itself is just structured storage. What turns it into a system that compounds across runs is the contract you define for what gets written into it. In our build, that contract is a pair of record types: Recommendation Records (RRs) and Decision Records (DRs). Anthropic provides the memory store. You decide what goes in it and how it is structured.
Every Recommendation Record is created before the meeting. It is what the system thinks the rep should do.
Every Decision Record is created after the meeting. It is what the rep actually did and what came of it.
The DR points back to the RR it resolved through a linked_rr field. That pairing is the chain the system learns from: recommendation → decision → outcome. Future runs can see both what was recommended and how it actually played out, which is what makes the corpus more than a logbook.
The schemas are strict YAML frontmatter on top of a markdown body, and the format is doing two jobs at once.
The YAML half is what makes the records queryable. Every key field, account, date, decision_type, account_attributes, is structured as a typed key/value pair, which means the decision-retriever can filter the corpus by exact attribute match. Without that structure, the retriever would be doing fuzzy text search over freeform prose, and matches would be unreliable. With it, “find me prior pricing decisions where procurement_complexity is vp_signoff” becomes a clean lookup.
The markdown body below the YAML is where the longer-form reasoning lives: the context, the rationale, the alternatives considered, the lessons in the generalized pattern. That part does not need to be queryable, just readable.
YAML specifically is doing one more useful thing: it is a format Claude (and most LLMs) handle natively, which means the recommender agents can produce schema-conformant frontmatter reliably without you needing a custom serializer. Together, the format gives you a record that is queryable from above and human-readable below.
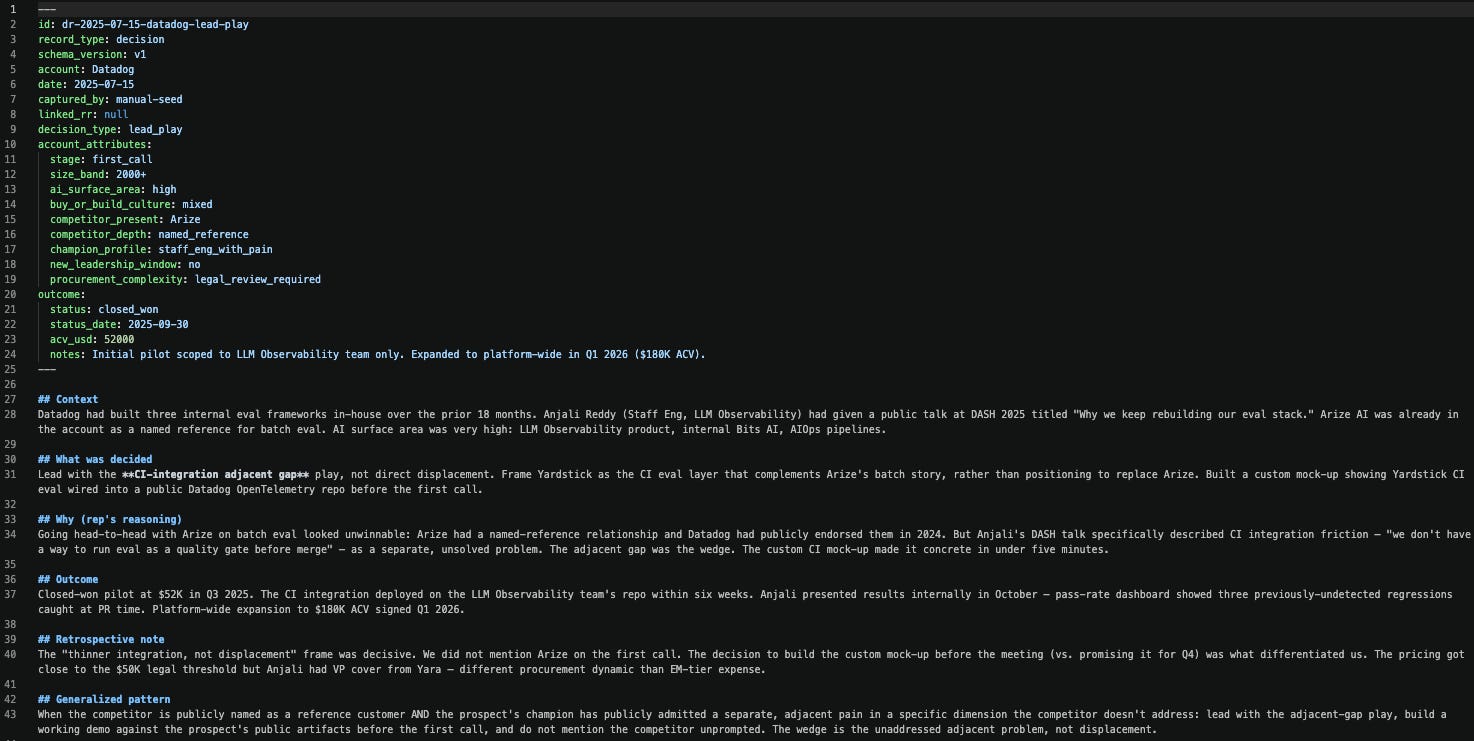
Recommendation Record schema
---
id: rr-{YYYY-MM-DD}-{account-lower}-{decision_type}
record_type: recommendation
schema_version: v1
account: {account_name}
date: {YYYY-MM-DD}
generated_by: {recommender agent name}
decision_type: {sequencing | lead_play | pricing | competitive_positioning | first_meeting_hypothesis | disqualification_threshold | risk_mitigation}
account_attributes:
stage, size_band, ai_surface_area, buy_or_build_culture,
competitor_present, competitor_depth, champion_profile,
new_leadership_window, procurement_complexity
linked_dr: null
cited_records:
- prior_rr: null
prior_dr: dr-{YYYY-MM-DD}-{account}-{decision_type}
prior_outcome: one-line outcome from the DR's outcome.notes field
relevance: which attributes match
lesson_applied: one-line lesson taken from the DR's Generalized pattern
---
## Context
## Findings that supported this recommendation
## Recommendation
## Reasoning
## Alternatives considered
## Generalized pattern
Decision Record schema (same shape as RR, with these fields added)
record_type: decision
linked_rr: rr-{...} # backfills the chain in the other direction
outcome:
status: {closed_won | closed_lost | stalled | pending | unknown}
status_date: {YYYY-MM-DD or null}
acv_usd: {number or null}
notes: one-line description of outcome
Body sections add ## What was decided, ## Outcome, and ## Retrospective note. The Generalized pattern section gets rewritten once the outcome is known, so the pattern is validated rather than hypothesized.
The account_attributes block is the filter the decision-retriever uses in Phase 1. When the system runs against a new account, the retriever filters the corpus for records whose attributes overlap. A new mid-market developer-tools account with a Braintrust competitor and a staff-engineer champion will pull back both the Vercel records and the Datadog records as prior decisions worth reasoning over. The retriever does not care whether the original account is Datadog or Vercel. It cares whether the shape of the account is similar enough to learn from.
The cited_records block is what makes the chain visible. Every RR carries an explicit list of prior DRs whose outcomes informed this specific recommendation. Each entry names four things:
prior_drid, which record is being citedprior_outcome, what happened (so the result behind the lesson is visible)relevance, whichaccount_attributesmatchedlesson_applied, the one-line rule the recommender is carrying forward
Multiple cited records may appear if the recommendation draws on more than one prior record. A reader of any RR can trace the reasoning back to the cited prior records by id, not by hand-waving.
Implicit and explicit capture of enterprise decisions
Records get into the corpus two ways.
Implicitly, through CRM record changes and activity logs the system watches without anyone narrating them. A stage change, a contract uploaded, a deal closed-won or closed-lost is itself a decision signal. The decision-recorder can infer a DR from those signals and write it with outcome.notes: inferred from CRM stage change. Implicit capture catches the cases where the rep forgot to debrief but state moved anyway. The records are useful but carry less reasoning, because no one narrated the why.
Explicitly, through a post-meeting debrief loop where the system asks the rep curated questions in Slack and the rep replies in-thread. The records that come out of explicit capture carry the rep’s own reasoning in their voice, which makes them the richest data the corpus has. Chapter 7 covers the mechanics of that loop in detail.
Cross-account learning in practice (from the actual run)
The Vercel pre-meeting run generated two Recommendation Records, one from the stakeholder-recommender and one from the competitive-recommender. Each one carries a cited_records block linking it to specific Datadog DRs by id. The sequencing RR’s cited_records block, taken directly from the corpus:
cited_records:
- prior_rr: null
prior_dr: dr-2025-07-22-datadog-sequencing
prior_outcome: "VP only met us once, at the closing call, with champion presenting the case."
relevance: "champion_profile=staff_eng_with_pain, sequencing, procurement_complexity=vp_signoff"
lesson_applied: "Do not engage the buyer directly when champion has standing with buyer. Equip the champion with internal proposal materials and let them own the internal sell."
- prior_rr: null
prior_dr: dr-2025-09-12-datadog-risk-materialized
prior_outcome: "Risk materialized in week 5; recovery move worked. Deal closed but 10 days later than original target."
relevance: "champion_profile=staff_eng_with_pain, single-threaded risk, secondary contact cultivation"
lesson_applied: "Secondary contact cultivation should be a pre-meeting deliverable, not a contingency. The secondary needs genuine engagement (their own use case), not just awareness."
The Reasoning section of the same RR cites those records by id in the body, not just in the frontmatter:
dr-2025-07-22-datadog-sequencing: Champion-led internal sell. VP met rep once at closing call. Direct structural match, Priya carrying to Marcus. Differs because Marcus is new (3 months in) and Priya’s standing with him is untested. Adaptation: explicit checkpoint and escalation triggers.
dr-2025-09-12-datadog-risk-materialized: Secondary contact cultivation saved the deal when champion went on leave. At Vercel, Tom Becker is the designated secondary with genuine AI Gateway/Production Monitor use case. Cultivation begins May 21, not mid-POC.
That paragraph is the entire reason the corpus exists. The system pulled two specific records from a different account, identified the load-bearing attributes, and applied the lessons with an adaptation for the Vercel-specific situation. It is structured reasoning over a corpus of prior decisions, filtered by attributes the engineer chose to make filterable.
The competitive-positioning RR follows the same shape, citing dr-2025-08-10-datadog-competitive and dr-2025-07-15-datadog-lead-play. Between the two RRs, the Vercel run cited four distinct Datadog DRs by id, with eight distinct lessons applied. None of that reasoning is hand-waved. All of it is structurally traceable.
Why this layer compounds
The platform’s memory store is durable, but durability alone does not produce learning. What produces learning is the schema contract that makes every write structurally identical and every read filterable. Once that contract exists, every run adds to the corpus, and every subsequent run benefits. The first Vercel run cited four Datadog DRs. The second Vercel run will also be able to cite the first Vercel run’s records. The third will cite both. The system gets better at giving you prep briefs because the substrate it draws on is growing in a way the retriever can actually use, and because every recommendation it generates is structurally tied to the prior records behind it.
Section 7: The async loop
The pre-meeting run finishes in fifteen minutes. The deal does not. After the call, the rep has information that did not exist before the meeting started, and the system needs a way to capture it. The capture step does not belong inside the pre-meeting orchestration. It runs on a fundamentally different timescale, against a different surface, with a different participant in the loop.
The build uses Slack as that surface and two standalone agents to run the loop: debrief-asker and debrief-synthesizer. Neither one sits in the coordinator’s roster. Both are agents in the same workspace, configured the same way as the pre-meeting specialists, but invoked independently when triggered.
The asker: curated questions, not generic prompts
After the meeting (or after a CRM event signals that a recommendation is due for resolution), debrief-asker runs. It is a standalone Managed Agents agent connected to the workspace’s Slack instance through the Slack MCP server. The asker reads the open RRs for the account, looks at the surrounding context (the recommendation made, the current account state, recent activity logs, calendar entries), and composes a curated set of debrief questions that target the specific decisions the RR was about.
The questions are not generic. They are shaped by what the system already knows about the account and which decisions are actually open. If the synthesis recommended a pricing structure but the CRM shows the deal has already moved to negotiation, the asker does not ask “did you discuss pricing”, it asks “did the $42K structure hold, and what did Marcus say about the legal-review path.” If a calendar entry shows a meeting happened with a stakeholder the system did not originally surface, the asker adds a question about that. The questions are surgical because the system already knows enough about the account to ask the right one.
The asker posts the curated set into a Slack channel scoped to that opportunity, so each deal has its own thread of capture. The rep replies in the thread whenever they have time. There is no UI to learn and no form to fill out.
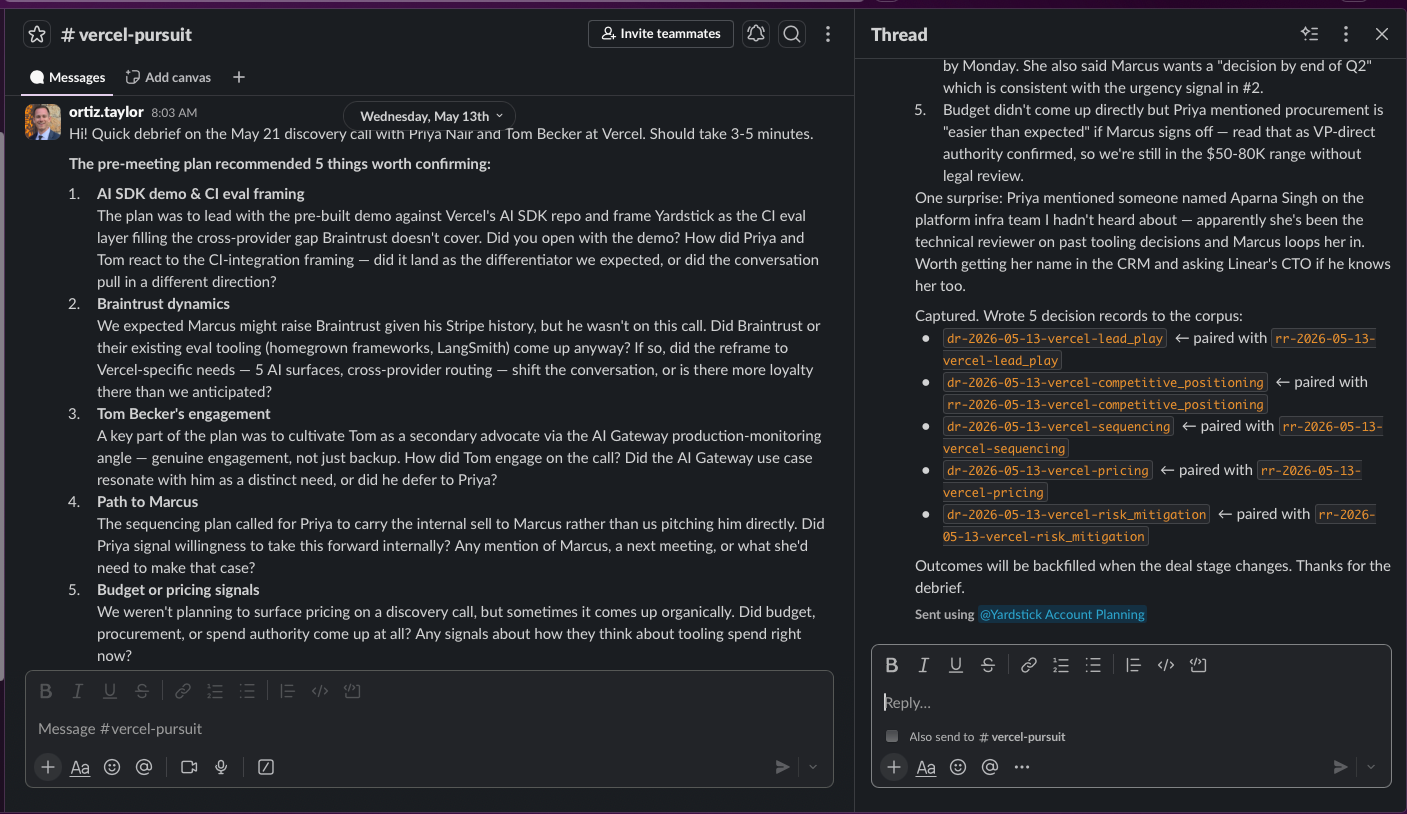
The synthesizer: schema-strict capture in the rep’s voice
Once there are replies, debrief-synthesizer runs. It reads the Slack thread through the same MCP server, parses the rep’s answers, and writes one Decision Record per resolved recommendation. The DR carries the rep’s reasoning in their own voice, plus a linked_rr pointer back to the originating RR. If the rep’s answer is ambiguous, the synthesizer marks the DR outcome.status: unknown rather than guessing. Schema integrity is more important than coverage.
The Slack MCP gotcha
The Slack MCP setup has one practical gotcha worth flagging. Slack MCP rejects bot tokens (xoxb-); it requires user tokens (xoxp-). The OAuth flow needs the user_scope parameter to capture a user-token, which the Anthropic vault stores as a static_bearer credential. The Slack app also has to be explicitly enabled at api.slack.com/apps/{app-id}/app-assistant for MCP access. None of this is in the Slack MCP getting-started docs at the time of writing.
The corpus is the integration point
The corpus is how the two flows connect. The pre-meeting orchestration writes RRs to it. The post-meeting agents read those RRs back, capture the rep’s debrief, and write DRs that point to the originating recommendation through linked_rr. The two flows never talk to each other directly. They just write to and read from the same store.
Section 8: The distillation layer
The output of an eleven-agent pre-meeting run is roughly eighty kilobytes of structured content across the orchestrator’s synthesis, the topic primers, the recommender RRs, and the supporting specialist outputs. A rep with thirty minutes before a meeting is not going to read eighty kilobytes. The system has done good work, but the work is locked up in an internal representation.
The second half of the architecture is the distillation layer: the part that reads the corpus and the run’s outputs and renders them into something a human can actually consume. In the build, that is build_dashboard.py, a script that produces a single static HTML page styled like a rep’s internal briefing document.
The dashboard pulls each specialist’s final reply from the events API and the corpus’s RRs from the memory store and lays them out as:
An account header (status, next meeting, owner)
The Phase 3 pursuit plan (opportunity-risk’s structured output)
The Phase 4 next-best-action RRs (each one with its
cited_recordsinline, so the cited prior records are visible at a glance)The Phase 2 topic primers (with smart questions for the meeting)
The stakeholder map (with named contacts and risk factors)
A collapsible “underlying intel” section (meeting-context plus external-researcher’s raw findings)
A sidebar showing the coordinator’s phase-by-phase narration log
A footer with session id, total cost, and a link to the Managed Agents console for the run
What the rep gets when they open the dashboard is a brief they can read in five minutes and act on in thirty. The pursuit plan tells them the play for the meeting. The recommendation cards spell out what to do next, each one with the cited prior records visible inline so the historical evidence sits right next to the recommendation. The topic primers give them the vocabulary they need to sound informed, each ending with a question they can ask in the room. The stakeholder map names the people they will encounter and what each one cares about. The sidebar shows the system’s narration, so any part of the reasoning is open to interrogate if the rep wants to dig in.
Section 9: What we learned, and when to use this
The five most important things we took away from this build.
1. The corpus compounds across runs.
Each run writes new records to the corpus. The next run filters the corpus by attribute overlap (industry, competitor, champion profile, procurement complexity, and so on) and pulls the most relevant prior records as input.
The first Vercel run cited four Datadog records by id, with eight specific lessons applied. Future runs will cite both the Datadog records and the Vercel ones.
Retrieval is deterministic and auditable. You can see exactly which prior records matched and why.
2. The cited_records chain makes every recommendation auditable.
Every recommendation carries a
cited_recordslist withprior_dr,prior_outcome,relevance, andlesson_appliedfields.Anyone reviewing a record can see which past decisions informed the recommendation and what specifically was carried forward from each.
The reasoning is traceable to specific past decisions by id.
3. The decision step is what makes the system multi-agent.
The coordinator inspects what each phase produced and decides what runs next.
On the Vercel run, the Phase 3.5 chooser invoked two of three recommenders and skipped the third with a substantive reason. That skip with a reason is the proof the decision step is real.
4. The agents do their own research. Ask them what they found.
The web-research agent went beyond the internal Notion notes and found Vercel’s CTO publicly endorsing Braintrust on the company blog. The synthesis flagged the original source as biased and reframed the position.
Adding one prompt at the end of the orchestrator’s narration (”if anything surprised you, note it”) produced disproportionately useful output. It surfaced a 1-pager the rep had left in drafts for two months and an unused Linear referral, neither of which any specialist was briefed to find.
5. Schema enforcement needs a code-level check.
We split content generation (recommender) from validation (recorder). The recorder is supposed to enforce schema.
The Phase 3.5 run still produced records with four extra fields and two missing required ones. The recorder wrote them anyway, because its validation is itself an LLM.
A JSON schema check in code before persistence catches what an agent’s system-prompt check misses.
When this is the right tool
Managed Agents multi-agent is the right tool when four things are true at once.
First, the work decomposes naturally into roles with different tool surfaces. If every specialist would call the same APIs and read the same context, the decomposition is artificial and a single agent with that tool set would do the same work with less overhead.
Second, you need at least one genuine decision step where the coordinator inspects what came back and decides what to do next. Without that, the system is a parallel reducer in a fancier wrapper, and any of the cheaper architectures (a workflow with parallel API calls, a single agent with multi-tool use) would do the same job for less.
Third, cross-run learning matters. The whole point of the corpus is that the system gets better the more it runs. If your use case is one-shot or stateless, you do not need persistent memory stores and the architectural overhead they bring.
Fourth, the output is consequential enough to justify the cost and latency. A pre-meeting prep brief that costs $5 and runs for fifteen minutes is fine when the meeting outcome is worth thousands. The same investment for a low-stakes task is overkill.