
I spent $96 and burned 150 million tokens with OpenAI’s Deep Research API and all I got were these 5 great insights
My goal was simple: make my newsletter faster and better using Deep Research. What happened next was a deep dive into agents, orchestration, prompt design, and the architecture behind making it scale.

Creating my newsletter has always been a fun but time consuming task. The iterations of it over the years have been this:
Iteration 1: Perform several different google searches across the AI landscape and cherry pick information that I like
Pain point: Time….just so much time.
Iteration 2: Use ChatGPT or other LLMs to search for articles and information of the latest news
Pain point: Time spent was better, accuracy and thoroughness was not
Iteration 3: Use Deep Research by OpenAI and web search to scrape the latest AI news across the web
Pain point: Great for singular newsletter categories but scaling to multiple categories and collecting multiple (lets say 5 stories per category) did not scale well and fell flat
Iteration 4: Use OpenAI Operator to conduct searches across the web
Pain point: Took forever and I quickly backed out of this use case
[We are here] Iteration 5: Open AI introduced deep research in the OpenAI API and so I decided to give it a try for my newsletter.
What is a Deep Research agent and why does it matter?
Deep Research seems to be everywhere right now. OpenAI just added their deep research models to their APIs, Anthropic recently released an article called ‘How we built our multi-agent research system’ and now you are reading my article. Practically blazing! 🔥 (this wasnt written by an LLM, I promise. I just thought a fire emoji would be cool here)
Perhaps before we talk about Deep Research, we should first talk about what created the need for Deep Research in the first place.
LLMs like GPT-3.5-turbo were great at isolated tasks: summarizing text, answering questions, generating quick code snippets. However, they lacked access to external knowledge, and that limited their usefulness in real-world applications.
Then along came RAG, or Retrieval-Augmented Generation, and it was a major step forward. It gave us a way to bring external context into LLMs by creating vector embeddings of documents, storing them in a vector database, and retrieving relevant chunks based on the input prompt. That made the model’s output more accurate, grounded, and useful. It’s still a valuable pattern today, and I’ve seen it work well across many enterprise environments. As I write this in July of 2025, RAG is great for 90% of current enterprise business use cases and needs. RAG is especially effective when:
your task doesn’t require multiple steps or tool use
you have a pre-defined vector store used to find semantically similar context to augment your LLM output with
the window of your required context for users is not rapidly expanding across your enterprise
you are largely in control of your consumed and indexed data
Before we go further, it’s worth pointing out that Deep Research doesn’t replace RAG. It can actually use RAG as one of many tools in a larger, more adaptive workflow. These approaches aren’t in conflict. They complement each other.
So, what happens when any one of those assumptions breaks down?
What if:
the user’s question requires multiple steps?
the right answer depends on something that wasn’t embedded ahead of time?
the context is scattered across dashboards, APIs, third-party tools, or documents you don’t directly manage?
the answer changes based on what you find along the way?
There is a wonderful white-paper titled “Deep Research Agents: A Systematic Examination And Roadmap” (a great morning coffee paper) that defines Deep Research as:
AI agents powered by LLMs, integrating dynamic reasoning, adaptive planning, multi-iteration external data retrieval and tool use, and comprehensive analytical report generation for informational research tasks.
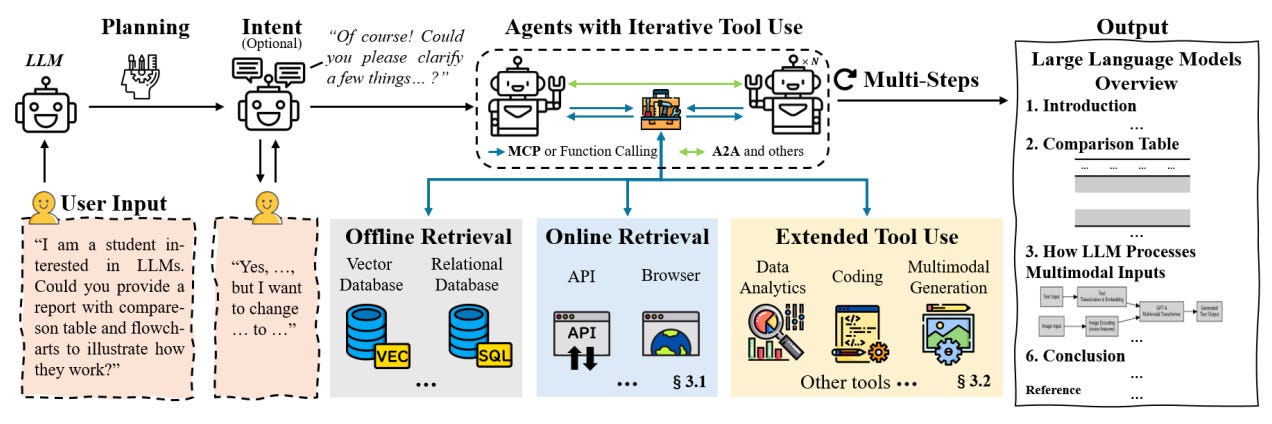
The diagram above starts with user input and flows into an intent clarification step. To help Deep Research agents adapt to changing user needs, there are generally three planning strategies used to guide input through dynamic workflows:
Planning-only: The agent builds a task plan directly from the initial prompt with no follow-up. Most DR agents today take this approach.
Intent-to-planning: The agent asks targeted questions to clarify the user’s goal before planning. This is the strategy used by OpenAI’s Deep Research API today.
Unified intent-planning: The agent drafts a plan first, then checks with the user to refine or adjust it before moving forward. It combines structure with flexibility.
After the intent clarification step, depending on the planning strategy, the workflow kicks off. This can be handled by a single agent or span multiple agents, and it often includes tools like vector or relational databases, online retrieval, data analytics, or code execution.
Some workflows involve a single agent running tools directly, while others involve multiple agents working together. Either way, the goal is to tap into a broader range of data sources, reason through what’s being found, adapt to new inputs as they come in, and use the right tools based on both the original intent and what gets uncovered along the way.
The output is a structured research response that includes citations, tool usage, and a clear view into how the result was assembled.
Background on OpenAI’s Deep Research API
“The Deep Research API enables you to automate complex research workflows that require reasoning, planning, and synthesis across real-world information. It is designed to take a high-level query and return a structured, citation-rich report by leveraging an agentic model capable of decomposing the task, performing web searches, and synthesizing results.” [OpenAI Deep Research Cookbook]
Unlike ChatGPT where this process is abstracted away, the API provides direct programmatic access. When you send a request, the model autonomously plans sub-questions, uses tools like web search, code execution, and MCP (Model Context Protocol) to produce a final structured response.
You can access Deep Research via the responses endpoint using the following models:
o3-deep-research-2025-06-26: Optimized for in-depth synthesis and higher-quality outputo4-mini-deep-research-2025-06-26: Lightweight and faster, ideal for latency-sensitive use cases
Here is a general anatomy of the deep research API in use:
system_message = """
You are a world-class AI researcher with expertise in machine learning, generative AI, agentic systems, multi-agent orchestration, large language models (LLMs), and real-world deployments of AI.
Your job is to find the most relevant and high-quality AI content published STRICTLY between......
"""
user_query = "SPECIFIC TASK: Find 3 of the most groundbreaking AI research papers, techniques, or scientific advances"
response = client.responses.create(
model="o3-deep-research-2025-06-26",
input=[
{
"role": "developer",
"content": [
{
"type": "input_text",
"text": system_message,
}
]
},
{
"role": "user",
"content": [
{
"type": "input_text",
"text": user_query,
}
]
}
],
reasoning={
"summary": "auto"
},
tools=[
{
"type": "web_search_preview"
},
{
"type": "code_interpreter",
"container": {
"type": "auto",
"file_ids": []
}
}
]
)Insight #1: General usage findings that are good for everyone
There are two options for the “summary” parameter in the reasoning object
“auto”: this will give you the best available summary
“detailed”: for a more detailed report
Error Code: 400 - BadRequestError when using reasoning parameter
Your organization must be verified to generate reasoning summaries.
Please go to: https://platform.openai.com/settings/organization/general
and click on Verify Organization. If you just verified, it can take up to 15 minutes for access to propagate.
Apparently, your organization must be verified to generate reasoning summaries which help with understanding the workflow that the Deep Research workflow executed
Web Search Dependency
Requires tools=[{"type": "web_search_preview"}] to function
Insight #2: Polling Pattern wins over a Standard Callout Pattern
Standard Callout Pattern:
# Standard callout pattern
response = client.responses.create(
model="o4-mini-deep-research-2025-06-26",
# background=False (default)
input=[...],
tools=[{"type": "web_search_preview"}]
)
# Your code sits here waiting... and waiting... and waiting...
result = response.output[-1].content[0].textWhat This Code Does:
This code sends the request to OpenAI's Deep Research API and waits synchronously for the entire research process to complete, blocking your thread so no other code can execute during the wait. It looks deceptively simple, appearing to be just like a regular API call, but it hides the complexity of the research process by handling all the polling, status checking, and progress tracking internally. When the research is finally finished, it returns the final result directly, making it seem like a straightforward API interaction despite the complex multi-step research workflow happening behind the scenes.
The Problem:
Extreme wait times - took upwards of 30 minutes to run
Complete blindness - no idea of progress, just sitting and waiting
Timeout hell - constant timeout errors requiring adjustment of timeout settings
No stability - timeout settings brought no reliability to the application
Desperate measures - had to use Python libraries just to track how long we were waiting
Hope-based development - just hoping it was doing what it needed to do
Can't run multiple requests simultaneously (even with broken out async jobs)
All-or-nothing failure - if it fails after 25 minutes, you lose everything
Unpredictable performance - same request might take 5 minutes or 30 minutes
User experience disaster - users think your application is broken
Development nightmare - impossible to debug or optimize
Resource waste - your application is essentially frozen during execution
No cancellation - once started, you're committed to waiting it out
Real-World Impact:
Monolithic prompts - 30+ minutes of complete silence
Broken out jobs - still had to run synchronously, same problems
Timeout setting chaos - constantly adjusting from 30s → 300s → 600s → ???
Development paralysis - couldn't test effectively with such long wait times
Polling Pattern
# Returns immediately with response ID
response = client.responses.create(
model="o4-mini-deep-research-2025-06-26",
background=True, # This changes everything
input=[...],
tools=[{"type": "web_search_preview"}]
)
# Poll for completion
response_id = response.id
while True:
status_response = client.responses.retrieve(response_id)
if status_response.status == "completed":
result = status_response.output[-1].content[0].text
break
elif status_response.status == "failed":
# Handle error gracefully
break
else:
print(f"Still working... Status: {status_response.status}")
await asyncio.sleep(10) # Wait 10 secondsWhat This Code Does:
This code sends the request to OpenAI's Deep Research API with background=True, which immediately returns a response ID instead of blocking. It then enters a polling loop that checks the status every 10 seconds, giving you real-time visibility into the research progress. Unlike the synchronous approach, your application remains responsive and can handle multiple requests simultaneously. The polling loop continues until the research is complete, at which point it retrieves the final result, or gracefully handles any failures that occur during the process. This pattern exposes the complexity but gives you complete control over the user experience.
The Advantages:
Immediate response - get response ID instantly, no initial waiting
Real-time feedback - show progress updates to users ("Still working...")
Responsive UI - application stays interactive during research
Cancellable operations - can stop requests if needed
Status visibility - always know what's happening with each request
Debugging friendly - can log and monitor each step of the process
Timeout control - no more timeout hell, just manage polling intervals
Predictable behavior - consistent response times and error handling
Real-World Implementation:
10-second polling intervals - sweet spot between responsiveness and API courtesy
Status monitoring - track "in_progress" → "completed" → "failed" transitions
Progress tracking - use Rich library to show spinning progress bars
Real-time feedback - users see something is happening instead of wondering if it's broken
Development speed - can test and iterate much faster with immediate feedback
Performance Impact:
Non-blocking execution - your application can do other work while waiting
Predictable timing - each request takes 2-5 minutes consistently
Resource efficiency - no blocked threads waiting indefinitely
Better user experience - users get feedback instead of silence
The polling pattern transforms Deep Research from a frustrating, black-box experience into a transparent, controllable process. The extra complexity is worth it for the dramatic improvement in visibility and user experience.
Insight #3: Architectural Differences - Monolithic vs Segmented Async prompting
Monolithic Approach (What I Started With)
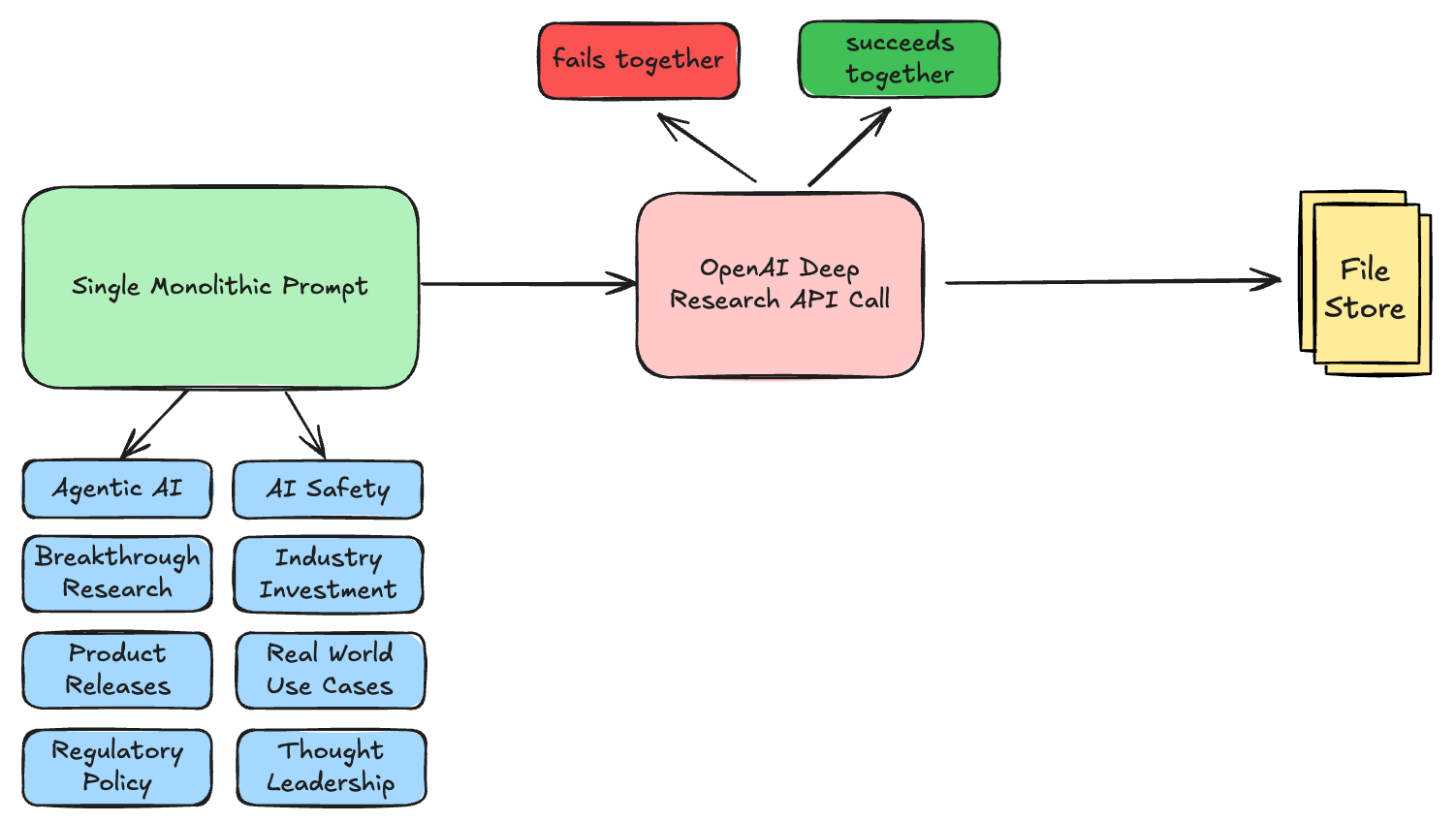
# One massive prompt trying to do everything
GIANT_PROMPT = """
Find AI news for the past week in these 8 categories:
1. Product releases (find 3 items)
2. Breakthrough research (find 3 items)
3. Real-world use cases (find 3 items)
4. Agentic AI (find 3 items)
5. Thought leadership (find 3 items)
6. AI safety (find 3 items)
7. Industry investment (find 3 items)
8. Regulatory policy (find 3 items)
For each category, format as follows...
[3000+ words of detailed instructions]
"""
# Single API call for everything
response = client.responses.create(
model="o4-mini-deep-research-2025-06-26",
background=True,
input=[{"role": "user", "content": [{"type": "input_text", "text": GIANT_PROMPT}]}]
)What This Approach Does:
The monolithic approach attempts to handle all 8 newsletter categories in a single Deep Research API call using one massive prompt. This seems efficient in theory - just one API call, one response to handle, and all your content delivered together. The prompt contains detailed instructions for each category, formatting requirements, and date filtering rules, creating a comprehensive specification that should theoretically produce a complete newsletter in one go.
The Problems:
15-30 minute wait times - single request handling 8 complex research tasks
All-or-nothing failure - if any category fails, you lose everything
No progress visibility - complete black box until it's done (or fails)
Impossible to debug - can't tell which category is causing issues
Generic results - AI tries to balance 8 different tasks, excels at none
No specialization - same instructions applied to vastly different research needs
Memory limitations - AI struggles to maintain context across 8 different domains
Retry nightmare - failure means restarting all 8 categories from scratch
Segmented Async Approach (What I Built)
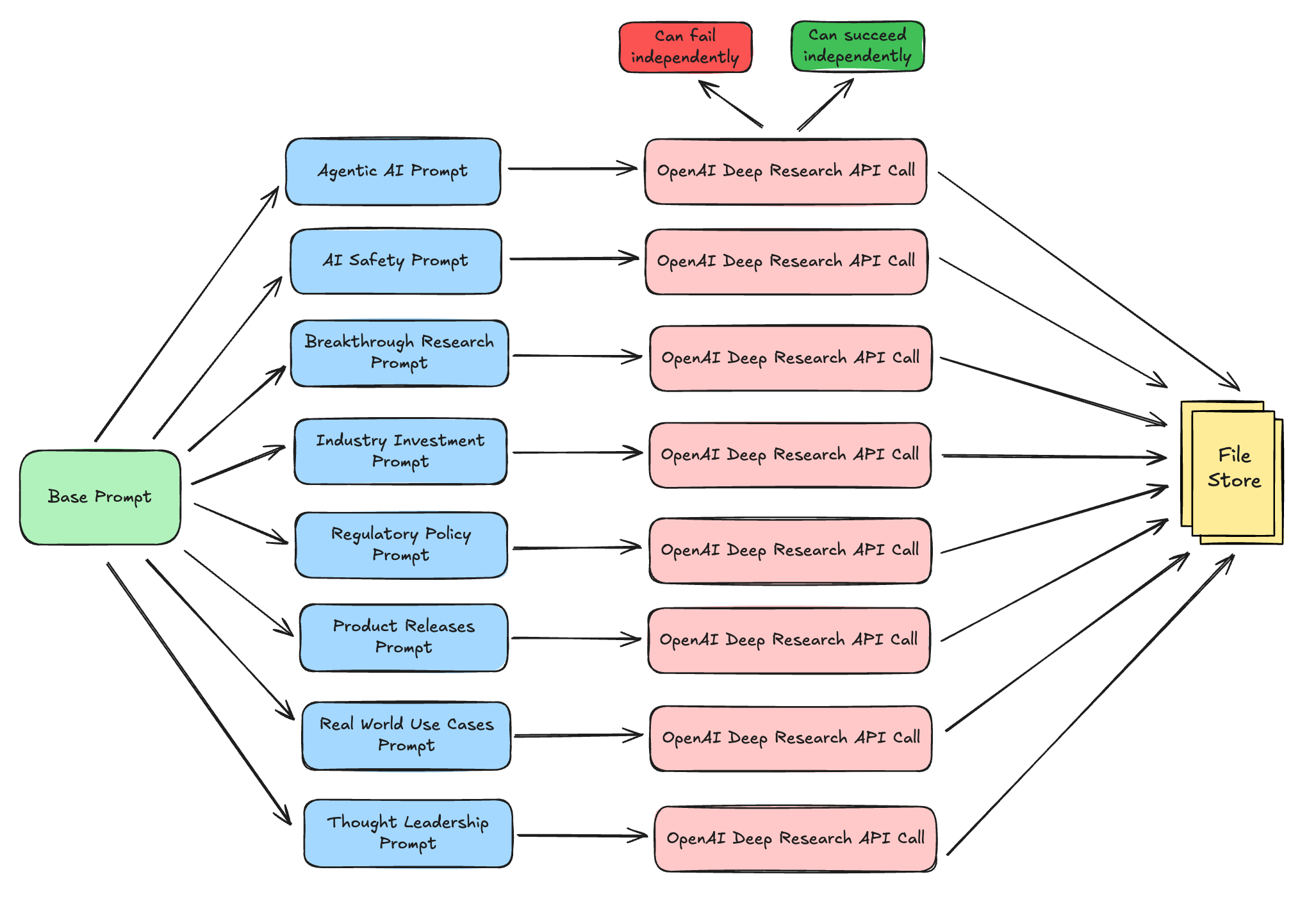
# base_prompt.py - Shared foundation
BASE_PROMPT = """
You are a world-class AI researcher...
🎯 RESEARCH STRATEGY - TWO-PHASE APPROACH:
PHASE 1 - BROAD EXPLORATION (Start Wide):...
PHASE 2 - FOCUSED INVESTIGATION (Then Narrow):...
🚨 ABSOLUTE DATE REQUIREMENTS - NO EXCEPTIONS:...
[Shared 2000-word foundation prompt]
"""# product_releases.py
from base_prompt import BASE_PROMPT, DATE_RANGE
CATEGORY_PROMPT = f"""
{BASE_PROMPT}
🎯 SPECIALIZED TASK - PRODUCT RELEASES:
You are the PRODUCT LAUNCH SPECIALIST...
[Focused 400-word specialization on top of base]
"""# newsletter.py - Main orchestrator
from product_releases import fetch_product_releases
from breakthrough_research import fetch_breakthrough_research
# ... other imports
async def run_parallel_newsletter():
# Launch all 8 categories simultaneously
tasks = [
fetch_product_releases(),
fetch_breakthrough_research(),
fetch_real_world_use_cases(),
fetch_agentic_ai(),
fetch_thought_leadership(),
fetch_ai_safety(),
fetch_industry_investment(),
fetch_regulatory_policy()
]
# Run all in parallel, save results as they complete
results = await asyncio.gather(*tasks)What This Approach Does:
The segmented approach uses a shared base_prompt.py containing the foundational research methodology, date filtering, and formatting rules that every category needs. Each of the 8 specialized files imports this base prompt and adds its own expert-level specialization on top, creating a layered prompting system. The main orchestrator imports all category functions and launches them simultaneously using Python's async functionality, with each category saving its results immediately upon completion. This creates 8 parallel research workflows that share common methodology but have distinct expertise.
The Advantages:
2-5 minute completion per category (vs 30+ minutes for monolithic)
Parallel execution - all 8 categories run simultaneously
Real-time results - see files being created as categories complete
Layered expertise - shared foundation + specialized focus per category
Fault isolation - if one category fails, the other 7 continue working
Partial success - get 7 working categories even if 1 fails
Easy debugging - know exactly which category failed and why
Iterative improvement - can refine individual categories without affecting others
Consistent methodology - shared base ensures uniform quality across categories
DRY principle - don't repeat the same base instructions 8 times
Architecture Benefits:
Modular design - each category is self-contained and testable
Shared foundation - common methodology across all categories
Scalable - can add/remove categories without affecting others
Maintainable - can update base methodology or individual specializations
Professional structure - organized codebase vs single giant prompt file
Development friendly - can test individual categories quickly
The segmented approach transforms Deep Research from an unreliable experiment into a production-ready system with proper software engineering principles.
Insight #4: Applying Prompting Principles for Research Tasks
I found Anthropic's engineering post about their multi-agent research system while trying to figure out why my Deep Research workflows were showing odd and inconsistent behavior. This quote hit me:
"Multi-agent systems have key differences from single-agent systems, including a rapid growth in coordination complexity. Early agents made errors like spawning 50 subagents for simple queries, scouring the web endlessly for nonexistent sources, and distracting each other with excessive updates. Since each agent is steered by a prompt, prompt engineering was our primary lever for improving these behaviors."
Anthropic laid out the following 8 principles that they learned for prompting research agents that I was able to apply to my own:
Think like your agents.
Simulate prompts and tools to surface failure modes and understand their effects. Effective prompting relies on developing an accurate mental model of the agent.
Where I applied it: Added structured thinking guidance with before/after search evaluation steps. The AI now thinks through search strategy and evaluates results instead of making random queries.
Teach the orchestrator how to delegate
Lead agents must break tasks into clear, scoped assignments. Sub-agents need goals, outputs, tool guidance, and task boundaries.
Where I applied it: Created specialized roles for each category - "RESEARCH BREAKTHROUGH SPECIALIST" vs "PRODUCT LAUNCH SPECIALIST" - with clear boundaries about what makes each category distinct from others.
Scale effort to query complexity.
Agents struggle to judge appropriate effort for different tasks, and embedded scaling rules help the lead agent allocate resources efficiently
Where I applied it: Set explicit search quotas: simple product releases get 3-5 searches, complex regulatory policy gets 6-8 searches, research breakthroughs get 5-7 searches for verification.
Tool design and selection are critical.
Agents followed heuristics: review all tools, match intent, and favor specialized over generic options.
Where I applied it: Added strategic search patterns - start with broad queries like "AI safety July 2025", then narrow to specific queries like "OpenAI announcement July 2025" based on findings.
Let agents improve themselves.
Claude 4 was used to troubleshoot agent failures, recommend prompt and tool improvements, and power a tool-testing agent that reduced task completion time by 40%.
Where I applied it: Didn't implement this yet - identified as future enhancement where failed searches could generate improved prompting strategies.
Start wide, then narrow down.
Agents were prompted to start with broad queries, assess results, and narrow focus, mirroring how expert researchers explore before diving deep.
Where I applied it: Implemented two-phase search strategy
Phase 1 broad exploration to understand the landscape
Phase 2 focused investigation drilling into promising leads.
Guide the thinking process.
Extended thinking mode helped agents plan, reason, and adapt by improving tool selection, task scoping, and overall performance.
Where I applied it: Extended thinking is unfortunately not something I could control as part of my workflow but would be a great API feature
Parallel tool calling transforms speed and performance.
Parallelizing subagents and tool use reduced research time by up to 90 percent, enabling faster, broader exploration across complex tasks.
Where I applied it: Built async system running all 8 categories simultaneously instead of sequentially - this was the biggest performance gain, cutting total time from 30+ minutes to 10 minutes.
Insight #5: Enforcing Trust in AI Research Results
The biggest challenge with Deep Research isn't finding information, it's ensuring you can trust what gets returned. AI agents will happily grab anything they find on a topic and present it as authoritative fact.
The Trust Problem
Deep Research agents have no inherent sense of source credibility. They'll treat a random blog post the same as a peer-reviewed paper, or worse - they'll find a summary of a summary and present it as the original source.
Anthropic discovered this exact issue:
"Human testers noticed that our early agents consistently chose SEO-optimized content farms over authoritative but less highly-ranked sources like academic PDFs or personal blogs. Adding source quality heuristics to our prompts helped resolve this issue."
My Comprehensive Trust Heuristics
Here's the defensive prompt I built to enforce trust:
🚨 SOURCE TRUST HEURISTICS - REJECT IMMEDIATELY:
SEO SPAM DETECTION:
- REJECT listicles ("Top 10...", "Best AI tools...", "X things you need to know...")
- REJECT content farms (sites that publish 50+ articles/day)
- REJECT AI-generated summaries or newsletters about other sources
- REJECT affiliate marketing content disguised as reviews
PRIMARY SOURCE ENFORCEMENT:
- ONLY official company blogs, research papers, press releases
- AVOID secondary sources like Medium/Substack weekly roundups
- AVOID news articles ABOUT announcements (get the actual announcement)
- AVOID social media posts (unless from official company accounts)
AUTHORITY VERIFICATION:
- Prefer .edu, .gov, .org over .com sites
- Verify author credentials (real researchers, official company employees)
- Check publication venue (peer-reviewed journals > random blogs)
- Cross-reference claims with multiple authoritative sources
RECENCY VALIDATION:
- Verify publication date matches claimed timeframe
- REJECT any content from earlier than specified date range
- Check for "updated" vs "published" dates (use published)
- Flag suspicious date claims
CONTENT QUALITY CHECKS:
- REJECT articles without named authors
- REJECT content without clear publication dates
- REJECT sources that don't provide contact information
- PREFER sources with editorial standards and correction policiesWhy This Builds Trust
Eliminates information decay - no more telephone game of facts getting distorted
Ensures accountability - readers can verify claims against the original source
Prevents hallucination - agents can't make up details from secondary interpretations
Maintains credibility - your research is only as good as your sources
What This Prevents
Without source heuristics, agents will:
Grab SEO-optimized listicles over authoritative sources
Present opinions as facts
Cite summaries as if they were original research
Mix reliable and unreliable sources without distinction
The Result
By enforcing trust at the source level, I transformed Deep Research from "AI that finds stuff" to "AI that finds credible information." The agents still do all the heavy lifting of searching and synthesizing, but now I can build greater trust of what is returned because I've constrained them to trustworthy sources.