
How Multi-Agent Systems Stay on Track When Users Change Their Minds
When users change direction mid-task, agentic systems need smart rerouting, not starting over. This pattern shows how to handle real-time pivots seamlessly.

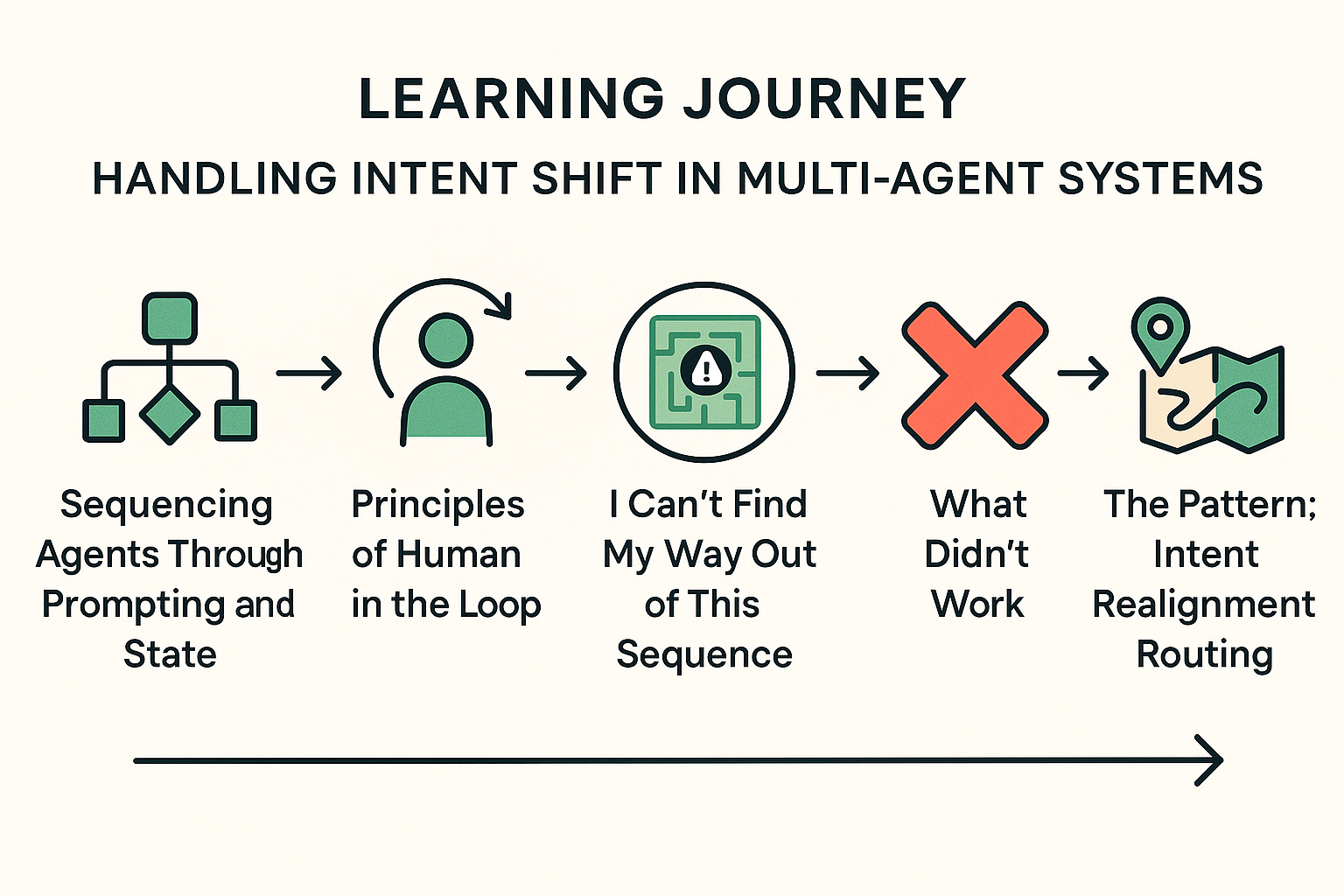
Learning Objectives
Above is our learning journey for today and after reading this post, you’ll be able to:
Explain how agent sequencing is influenced by prompting and state.
Describe key principles of human-in-the-loop design in multi-agent orchestration.
Identify failure points when a user shifts intent mid-conversation.
Apply a design pattern to recover gracefully from flow-breaking interruptions.
First, let’s pretend that you are building a recipe finding and grocery shopping assistant with multi-agent capabilities. Your assistant will find recipes, extract the ingredients from those recipes, search for those ingredients using an operator, add ingredients to your cart, check out and order your groceries for pick up or delivery.
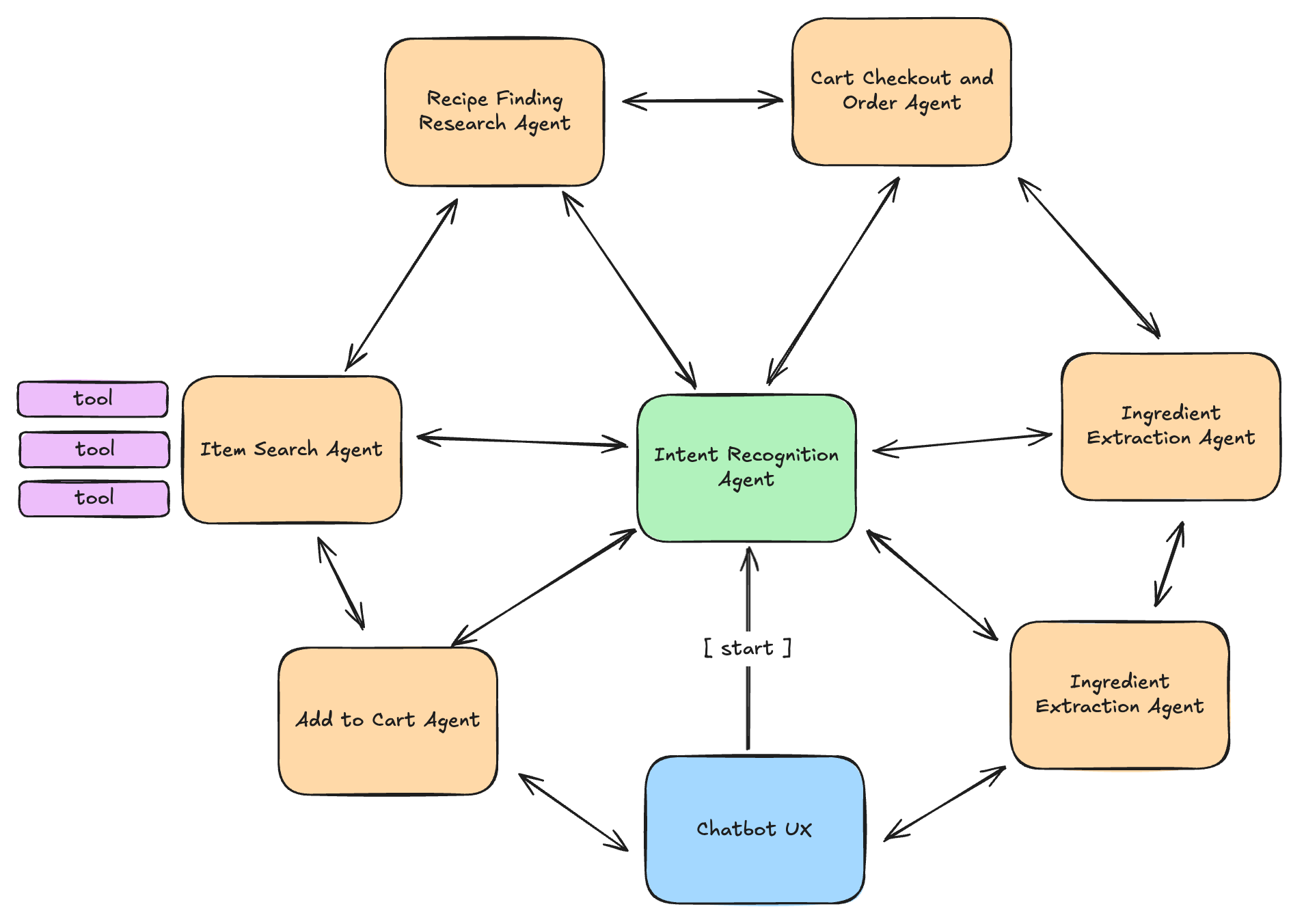
There are other ways to design this multi-agent orchestration, but for this example we will go with the architecture illustrated above. Common nomenclature for this particular pattern of multi-agent architecture is called the Network pattern. A term that I made up that I often refer to with clients is Wagon Wheel Agent Architecture.
Usually, at the start of the conversation, there is an intent recognition agent that is prompted to return back the next agent to call, either dynamically or conditionally, based on the input and context provided by the user at the onset of the conversation.
In this setup, every agent can talk to every other agent. Each agent has the ability to decide who to call next, which makes it a great fit for use cases where there isn’t a strict hierarchy or a fixed sequence to follow. It’s flexible by design, and that flexibility opens up more room for adaptability mid task.
Sequencing Agents Through Prompting and State
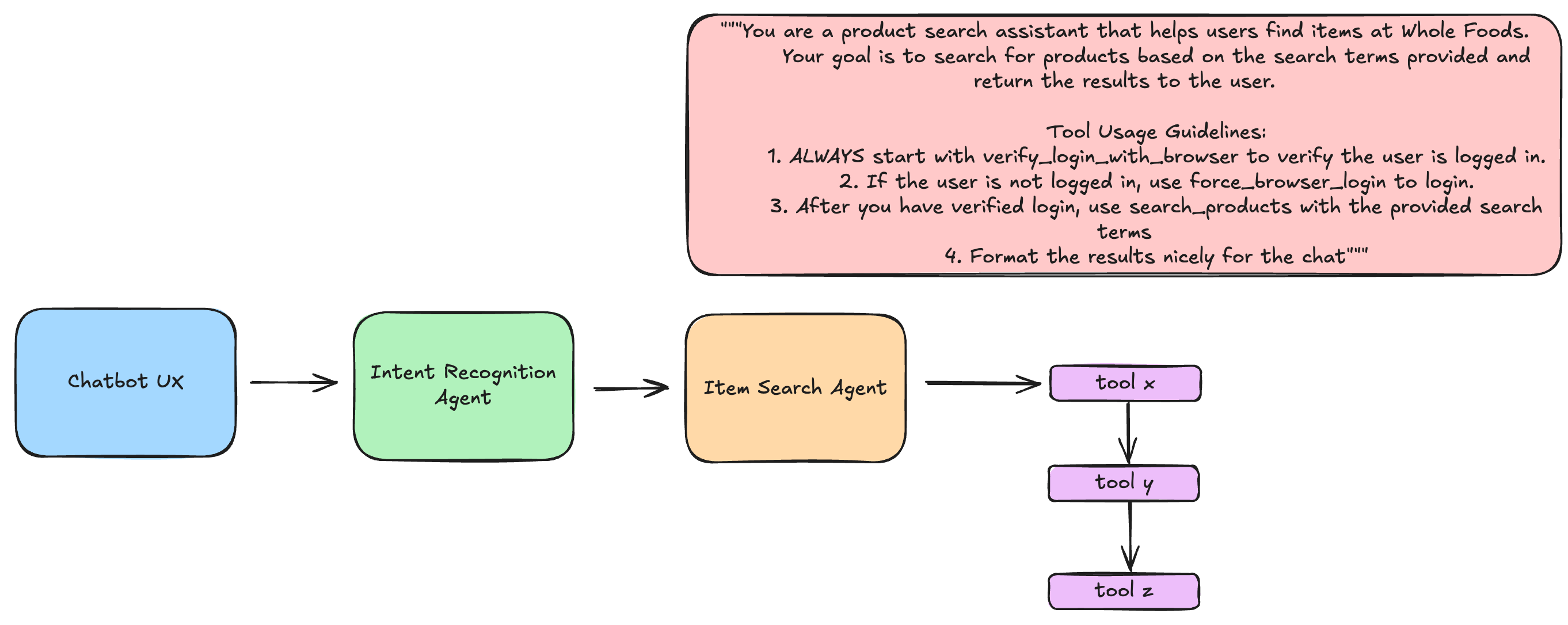
Prompting is incredibly important when it comes to any agentic orchestration and especially when we enter into “sequence” of tool calling for an agent. In the example above, I am prompting the agent to pick the right sequence of tooling as it relates to the flow and conditions I want to consider. In this case, the flow is pretty linear, but it could require an extensive amount of instructions that your agent needs to follow so that it can reasonably identify its sequence and understand how it should impact the overall state.
So how do we do that?
We give the prompt context into which agents it has to choose from and insight into what those agents do and why they are important.

This is just an example for the sake of explaining and the real estate on the page, but this would normally be a very extensive explanation for the prompt to have the context it needs to reason. The critical part is the next_agent key that the JSON object is utilizing and returning after the agent sequence has completed so that the orchestrator knows what to do next. Lets examine the code below.
def agent_1(state: MessagesState) -> Command[Literal["agent_2", "agent_3", END]]:
response = model.invoke(...)
return Command(
goto=response["next_agent"],
update={"messages": [response["content"]]},
)
def agent_2(state: MessagesState) -> Command[Literal["agent_1", "agent_3", END]]:
response = model.invoke(...)
return Command(
goto=response["next_agent"],
update={"messages": [response["content"]]},
)Key things about the code above:
You can pass relevant parts of the state to the LLM or the whole thing (e.g., state["messages"])
To determine which agent to call next, a common pattern is to call the model with a structured output (e.g. force it to return an output with a "next_agent" field)
Route to one of the agents or exit based on the LLM's decision
This is the next_agent key we saw in our previous prompt that is managed by the agent
If the LLM returns "__end__", the graph will finish execution
The update parameter in the Command object is a driving force for state influence for the next agent that is invoked.
ie. Think of update as your control panel for influencing downstream behavior. If your agent modifies state during tool execution, you're effectively shaping how the rest of the system responds from that point forward.
This is how we achieve dynamic routing with our agents that are totally controlled by the state, reasoning and tool sequence of the prior agent execution. We can always be more explicit than this and direct the next agent execution in a more hard coded fashion, but for the sake of this post, I am showing you dynamic routing because this is how we will establish our intent change pattern below.
Principles of Human-in-the-loop
Alongside agentic flows and tools sequences, we also have the ability to halt the flow to collect user feedback. If you want to review, edit, or approve tool calls within an agent or workflow, you can build in human-in-the-loop checkpoints that allow for intervention at any stage of the process.

There are a few common patterns I use when working with human-in-the-loop:
Approve or reject actions
You can pause the flow before something important happens, like an API call, and give a human the chance to review and approve it. If it gets rejected, you can either skip that step or reroute the workflow based on that input.
Edit the graph state
Sometimes you want to stop and let a human tweak the state (ie. like fixing a mistake or add missing info. That updated state can then shape how the next agent behaves.)
Review tool calls
Before an agent runs a tool, you can pause and have a human look over the tool call. They can make edits if needed before it moves forward.
Validate human input
You can also pause the workflow to double-check that a human-provided input is accurate or complete before continuing on to the next step.
Essentially, this means that we can add components to our agent sequence that actually interrupt the flow and ask for user input. Below is a code example of this in practice using LangGraph:
from typing import Literal
from langgraph.types import interrupt, Command
def human_approval(state: State) -> Command[Literal["some_node", "another_node"]]:
is_approved = interrupt(
{
"question": "Is this correct?",
# Surface the output that should be
# reviewed and approved by the human.
"llm_output": state["llm_output"]
}
)
if is_approved:
return Command(goto="some_node")
else:
return Command(goto="another_node")Here is what the code above is doing:
Defines a function human_approval that takes in a state object and returns a Command.
Uses the interrupt function to pause execution and ask a human:
“Is this correct?”
Includes state["llm_output"] in the interrupt payload to give the human context for the decision.
Waits for a human response (True or False) to the approval prompt.
If the human approves (True), it routes to the "some_node" agent.
If the human does not approve (False), it routes to the "another_node" agent.
This pattern enables human-in-the-loop validation and conditional branching in a LangGraph agent workflow.
I Can’t Find My Way Out of This Sequence
We just read about:
How to influence agent sequence outcomes with prompting and tooling
Some principles and types of human-in-the-loop design for multi-agent orchestration
The reason we spent some time covering these two areas is to get to the problem statement:
How can we be defensive in our orchestration when a human interrupts the flow and shifts intent, without derailing the system, sacrificing user experience or losing meaningful state for future interactions?
A Common Scenario
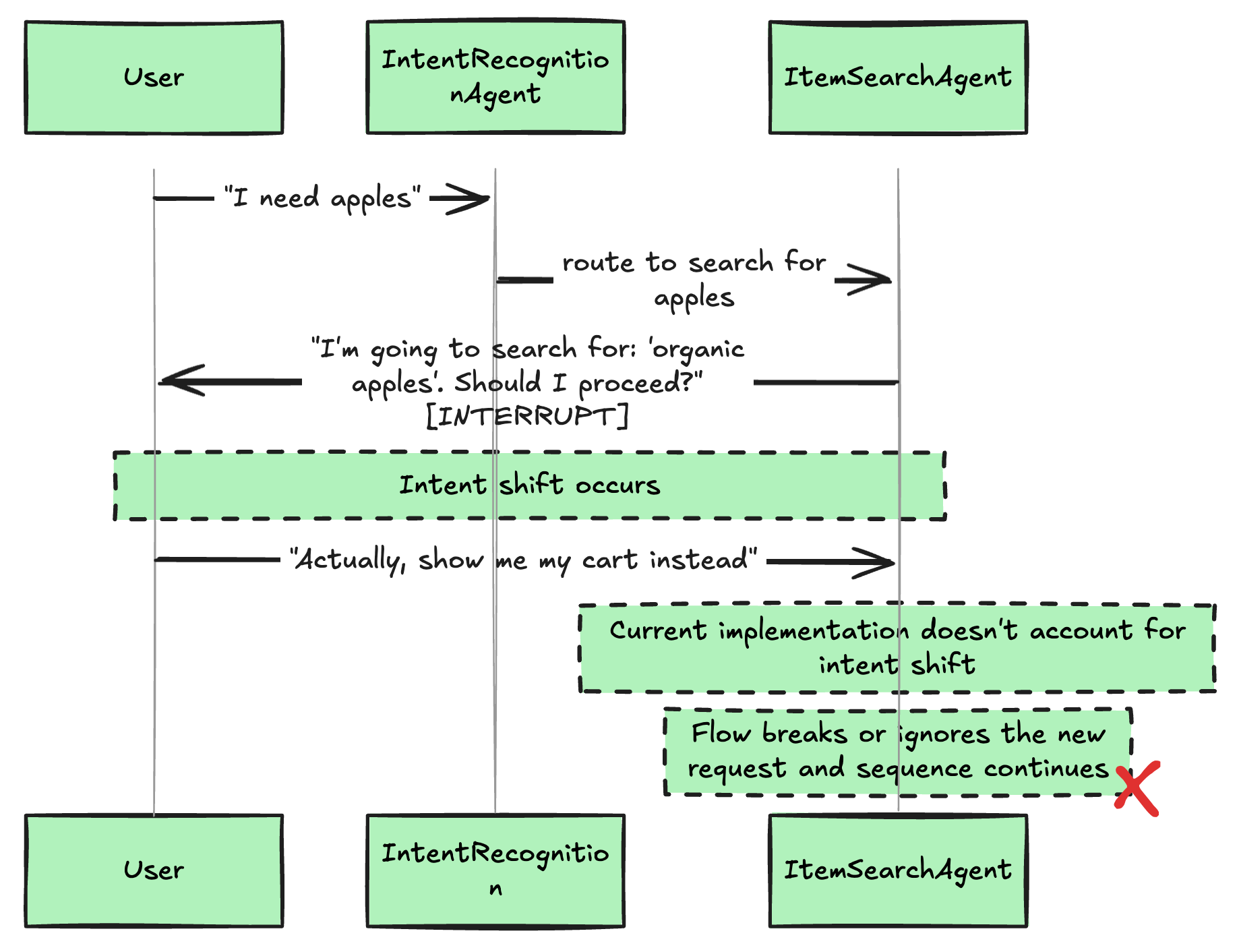
This diagram shows a conversation that took an unexpected turn. The user started wanting apples, but mid-conversation decided they wanted to see their cart instead. The current implementation can't handle this gracefully.
Why This Breaks User Experience
When users hit this wall, they feel like they're talking to:
A rigid IVR system ("Press 1 for search, press 2 for cart...")
A collection of separate tools rather than one intelligent assistant
A chatbot that doesn't actually understand conversation flow
The Technical Challenge
Agent Ownership: Once an agent controls the conversation, how do you break out?
Context Preservation: How do you maintain state when switching between agents?
Interrupt Complexity: Traditional interrupts expect yes/no, not complete direction changes
What Didn’t Work
What Didn’t Work: Using just the interrupt() function alone
The Approach
The most obvious approach was to use LangGraph's interrupt() function directly for human-in-the-loop interactions. At first glance, this seemed like exactly what we needed: pause execution, get user input, and continue based on their response.
def human_approval(state: State) -> Command[Literal["some_node", "another_node"]]:
is_approved = interrupt(
{
"question": "Is this correct?",
# Surface the output that should be
# reviewed and approved by the human.
"llm_output": state["llm_output"]
}
)
if is_approved:
return Command(goto="some_node")
else:
return Command(goto="another_node")What this Code is Doing:
the
interrupt()function is asking a question to the user about whether the state of the llm_output is correct. This pauses the flow.Once the user responds, the response is provided as a string back to the interrupt function
is_approved is checked and based on the value, it is routing accordingly to the next agent
What Interrupt Is:
A pause/resume mechanism - It stops execution and waits for input
A control flow tool - It manages when and how execution continues
A simple data exchange - It sends context to the user and receives their response
What Interrupt Isn’t:
An analysis engine - It doesn't understand or interpret responses
An intelligent system - It has no reasoning capabilities
A decision maker - It can't determine what the user's response means
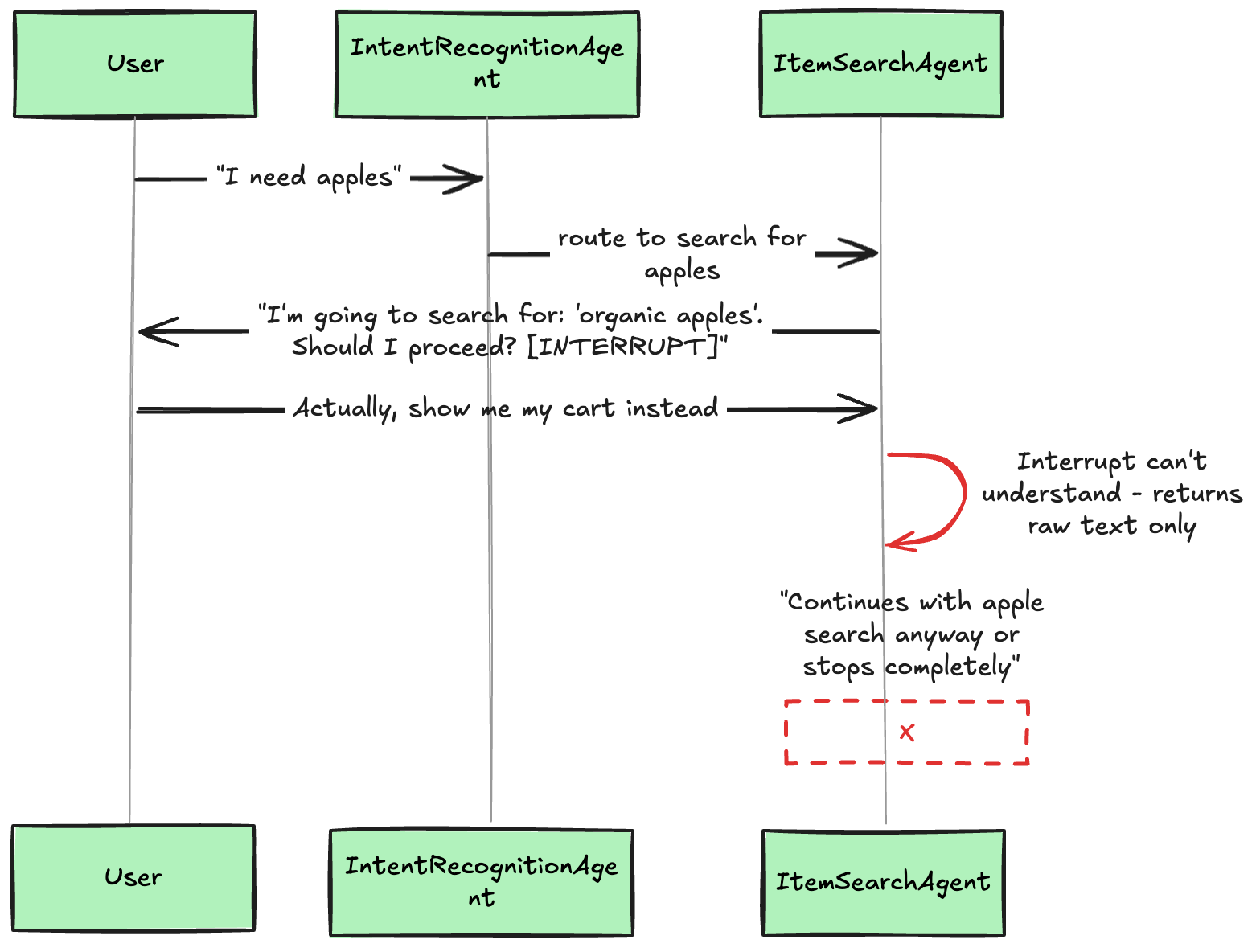
Why this alone wasn't enough:
The interrupt() function is purely a data transport mechanism that returns raw user input as strings, with no reasoning or interpretation. This creates fundamental instability:
Raw string returns: interrupt() returns exactly what the user types - "yes", "no", "I like salsa", "Actually, show me my cart instead" are all just strings
No semantic understanding: The function cannot distinguish between meaningful responses ("show me my cart") and nonsense ("I like salsa")
Requires exhaustive pattern matching: Every possible user input must be explicitly handled, or you need an arbitrary fallback
Brittle base cases: When users type anything unexpected, the system must make arbitrary decisions about what to do next
Since interrupt() provides no reasoning capabilities, every implementation must include a catch-all else clause that makes arbitrary decisions for unrecognized inputs. This means the system's behavior becomes unpredictable and often wrong when users deviate from expected responses.
What Didn't Work: Adding an LLM Analysis Layer
The Approach
The second approach I tried was adding a separate LLM call between the user's response and the agent's decision. The idea was to use interrupt() to get the raw user input, then have a dedicated analysis function determine what the user actually meant before proceeding.
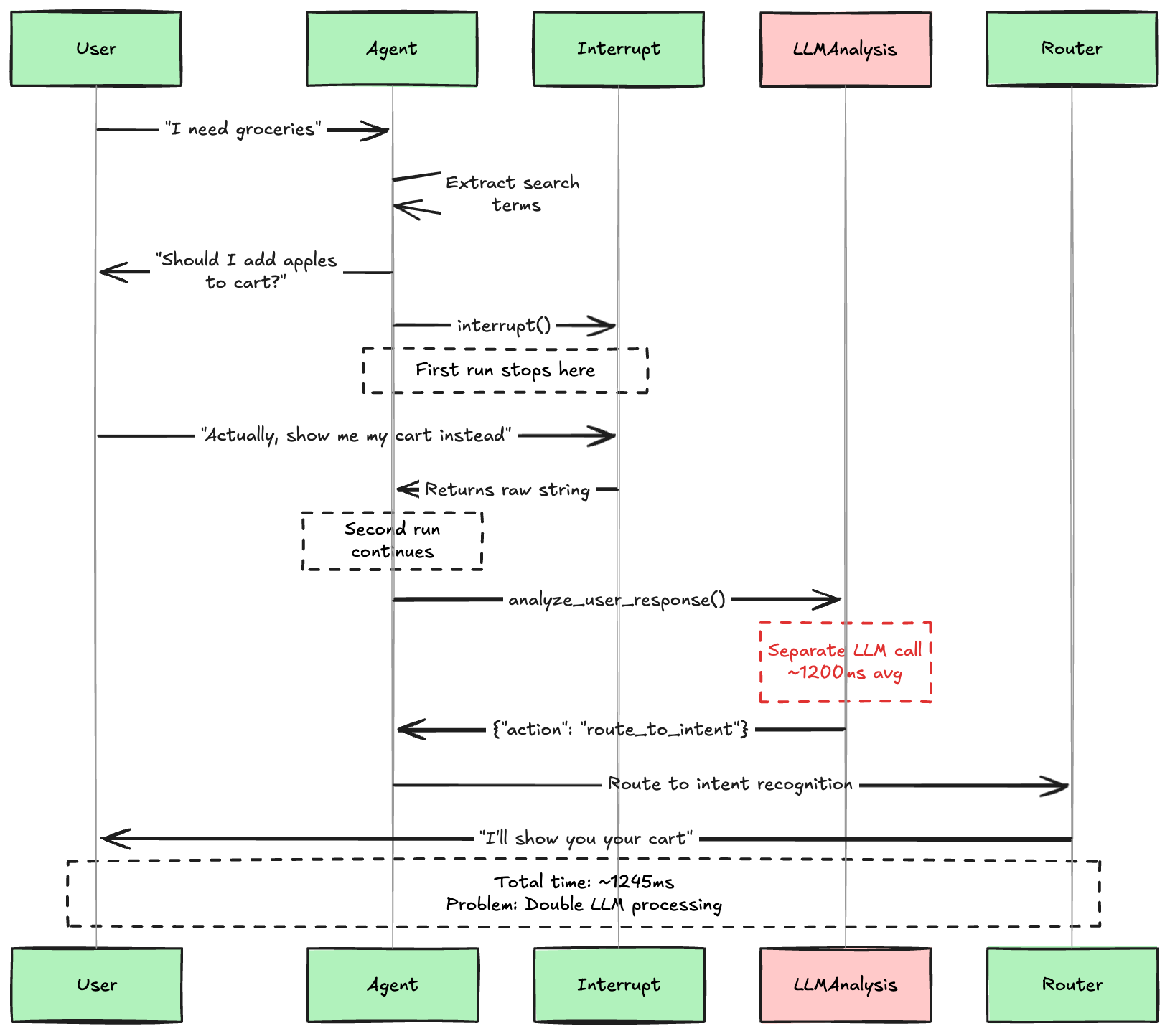
What This Approach Got Right
This approach successfully solved the intelligence problem. Our testing showed it could accurately distinguish between:
Direct answers: "yes" → proceed, "no" → cancel
Intent changes: "Actually, show me my cart instead" → route to cart viewing
Different intents: "What stores are available?" → route to store information
Nonsense responses: "I like salsa" → ask for clarification
The Performance Problem
However, this approach came with a significant performance cost:
Average response time: 1,245ms per user interaction
Double LLM processing: One call for analysis + one for the agent's main task
Noticeable latency: Over 1 second delay is perceptible to users
Architectural complexity: Separate analysis functions, error handling, and routing logic
Why This Wasn't Sustainable
While functionally correct, this approach created a poor user experience. Every time a user responded during a human-in-the-loop interaction, they had to wait over a second for the system to:
Analyze their response with the first LLM call
Route based on that analysis
Execute the appropriate agent logic
This double-processing pattern would be especially problematic in conversational flows where users might change direction multiple times.
The Pattern: Intent Realignment Routing
Things changed when I read this note in LangGraph’s documentation.
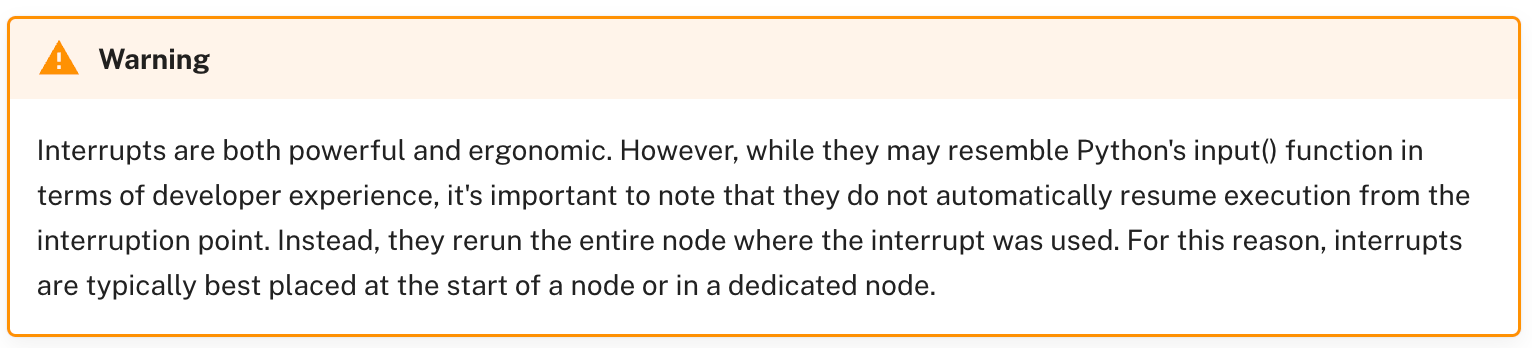
The Realization
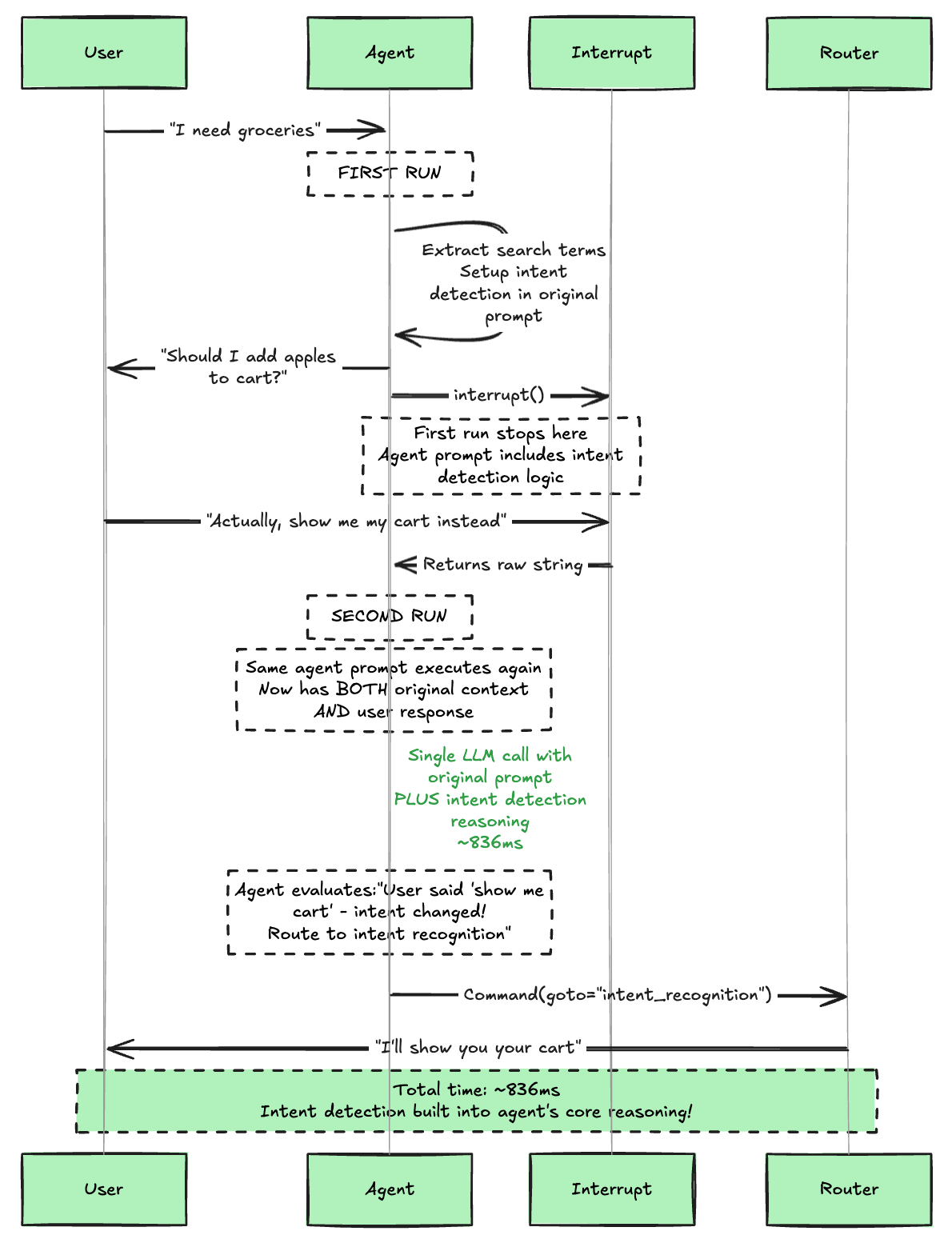
The breakthrough came from understanding how LangGraph's interrupt mechanism actually works. Since interrupt causes nodes to rerun entirely, agents naturally have access to both the original context AND the user response on the second execution. Instead of treating intent detection as a separate analysis step, we could integrate it directly into the agent's core reasoning.
The Pattern
The key insight was simple but powerful: make intent detection part of the agent's natural decision-making process. Instead of asking "what did the user mean?" in a separate step, the agent asks "given what the user just said, what should I do next?" as part of its core reasoning.
# THE BREAKTHROUGH: Intent detection integrated into the agent's core prompt
agent_response = model.invoke(f"""
You are a grocery search agent helping users find items to purchase.
[... agent context, instructions, and main task logic ...]
I extracted search terms: {search_terms}
I asked the user: "Should I proceed with searching for {search_terms}?"
User responded: "{user_response}"
DETERMINE THE USER'S INTENT:
Analyze the user's response and classify it into one of these categories:
1. CONFIRMATION: The user is agreeing to proceed with the current search task
→ Action: continue_search
2. REJECTION: The user is declining or canceling the current search task
→ Action: cancel_search
3. REDIRECTION: The user is requesting a different action or asking about something unrelated to the current search
→ Action: route_to_intent
Consider the semantic meaning of their response, not just specific words. What is the user actually trying to communicate?
[... rest of agent reasoning and response formatting ...]
Return JSON: {{"action": "continue_search|cancel_search|route_to_intent", "reasoning": "brief explanation"}}
""")Why This Works
This approach leverages the two-phase execution pattern elegantly:
Phase 1: Agent runs, asks question, interrupts
Phase 2: Agent runs again with user response, naturally incorporates intent analysis into its decision-making
The agent doesn't need a separate "intent detection" function - it naturally reasons about whether to continue its task or help the user with something else.
The Performance Results
Testing showed dramatic improvements:
The Rerun Pattern: 836ms average response time
LLM Analysis Layer: 1,245ms average response time
Performance Gain: 33% faster with single LLM call instead of double processing
The Elegant Architecture
This pattern creates a beautifully simple architecture:
Single responsibility: Each agent handles its own intent analysis
No separate analysis functions: Intent detection is built into core reasoning
Leverages LangGraph naturally: Uses two-phase execution as designed
Maintains conversation coherence: The same agent that started the conversation handles the response
Conclusion
The breakthrough wasn't just about performance - it was about finding the natural way to handle human-in-the-loop interactions in LangGraph. Instead of fighting against the interrupt mechanism with separate analysis layers, we worked with it to create an elegant solution that's both faster and more maintainable.
By integrating intent detection into the agent's core reasoning process, we solved the fundamental challenge of graceful direction changes in conversational AI. Users can now seamlessly switch between different intents mid-conversation, and the system responds intelligently without the latency penalty of double LLM processing.
This pattern is now the foundation of our multi-agent grocery shopping assistant, enabling truly natural conversations where users can change their minds, ask questions, and explore different options without breaking the conversational flow.