
Can LangChain DeepAgents Explain a Codebase Architecture?
I used LangChain Deep Agents with async subagents to crawl real GitHub repos, map their architecture, generate diagrams, and check every claim against source files.

I wanted to know whether LangChain DeepAgents could help me build real architectural understanding of an unfamiliar codebase faster.
The test was to point it at a real repository, ask it to produce an expert-level architecture dossier, and see whether the output could teach me the system well enough to make better engineering decisions.
I ended up building a repo architecture workflow with a deterministic source crawler, async area subagents, a claim ledger, a diagram architect, and validation against source files.
The result was genuinely useful. After one full run, I had a clear map of the DeepAgents repo, the main packages, the core files, the extension points, the async subagent implementation, and the reading path I would follow if I were onboarding into the codebase cold.
What is a Deep Agent anyway, and why should you care?
The simplest way to think about a Deep Agent is an agent built for longer, messier work.
In LangChain’s DeepAgents package, a supervisor agent can use tools, filesystem context, and subagents to work through a task that would be awkward as one prompt. The supervisor owns the final answer. The subagents take bounded pieces of the work. The filesystem gives the run somewhere to keep intermediate artifacts like reports, notes, source packets, and plans.
That matters for codebase architecture because the work has a natural shape. You need to inspect the repo, split it into meaningful areas, read files in each area, compare claims against source evidence, and then turn the whole thing into a mental model a human can use.
DeepAgents also has AsyncSubAgent, which is especially interesting for this use case. An async subagent is launched as a background Agent Protocol task. The supervisor gets a task id back, can check status later, and can update the task if it needs a revision.
That maps really cleanly to architecture learning. A monorepo has separate threads of work. libs/deepagents, libs/cli, libs/code, examples, .github, and partner integrations can all be studied independently before synthesis.
The use case
The job was:
Given a GitHub repo, produce a source-grounded architecture dossier that helps a developer build expert-level understanding of the system: how it is organized, where the important code lives, how the major pieces interact, which abstractions matter, what evidence supports each claim, and what to read next.
This is the kind of work I do constantly when opening a new codebase. I want to know:
What kind of repo is this?
Where is the real architecture root?
What are the major packages or areas?
What are the core abstractions?
How does the main flow work?
How do the important packages depend on each other?
Which extension points are real contracts?
Which files should I read first?
Which claims are grounded in source, and which ones are guesses?
The target repo for the full run was the DeepAgents repo itself. So the experiment became recursive in a useful way: use DeepAgents to understand DeepAgents.
What I built
The workflow has three layers.
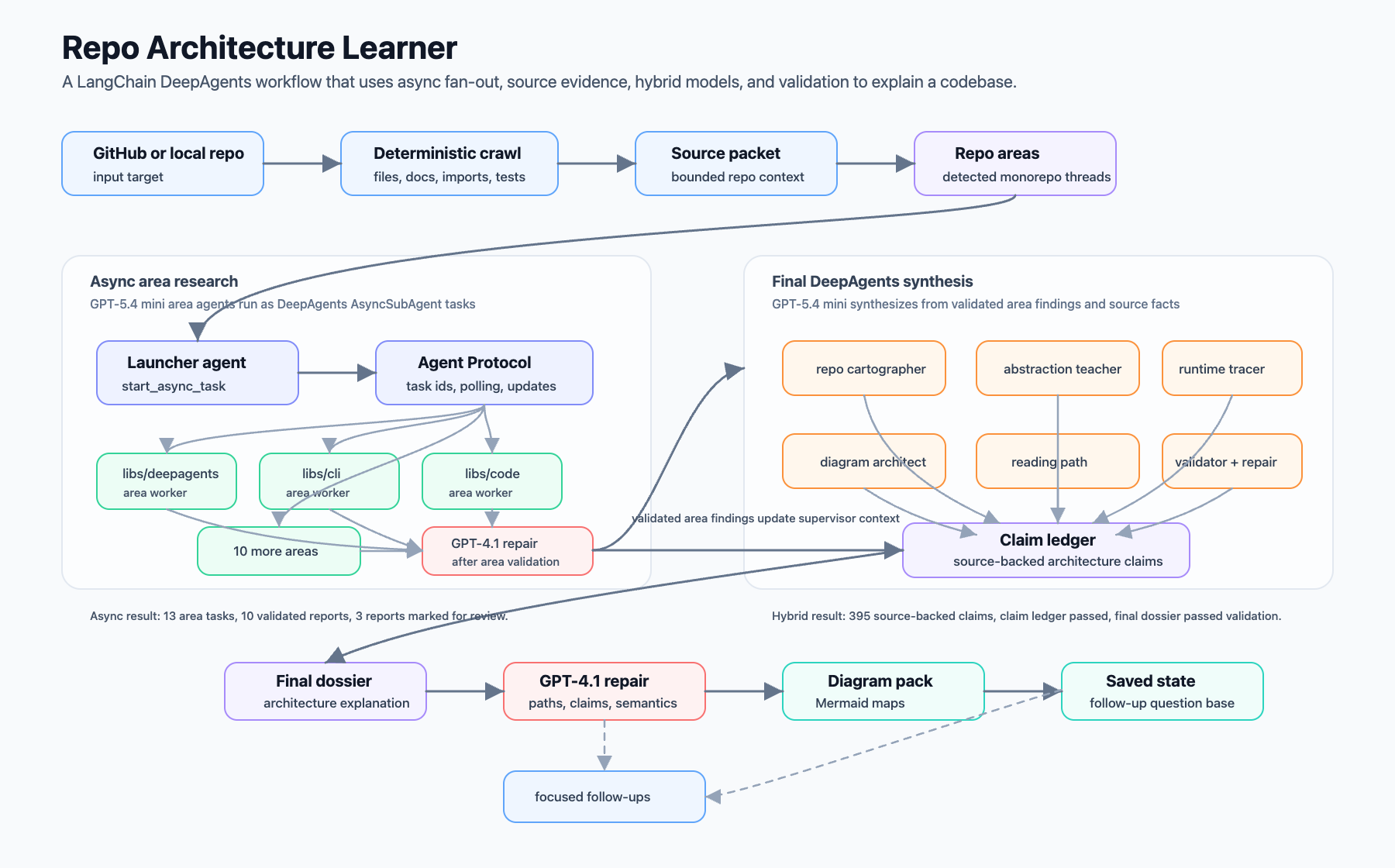
The first layer is deterministic. Before calling the model, the system crawls the repo and builds a source packet. That packet includes the repo shape, detected package areas, entrypoints, central files, docs, configs, tests, and resolved internal import edges.
The second layer is the agent workflow.
For the monorepo fan-out, I used DeepAgents AsyncSubAgent.
The official LangChain AsyncSubAgents docs describe them as a way for a supervisor agent to “launch background tasks that return immediately.” The supervisor can keep working while those tasks run, then check progress, send follow-up instructions, or cancel work if needed.
That fit this use case almost exactly. Each detected repo area gets its own background area-deep-dive task through a local LangGraph Agent Protocol server. Each async worker gets a bounded assignment, fetches source files for that area, and returns two artifacts:
a Markdown area report
a structured JSON finding set
Those area workers are the expensive part of the run, and they are the part that benefits from async. They can inspect different repo areas at the same time and then flow back into the final synthesis.
The handoff back to the supervisor is the important part. Each async area subagent returns a validated finding set and area report. The runner turns those into a consolidated area dossier bundle, then passes that bundle into the final DeepAgents supervisor as source-grounded context. If an area report fails validation, the same async task thread gets an update asking it to repair the report before the supervisor uses it.
The final synthesis uses a DeepAgents supervisor with regular specialist subagents:
repository area mapper
repo cartographer
abstraction teacher
runtime flow tracer
diagram reviewer
diagram architect
reading path teacher
architecture validator
That sync versus async split felt right. The area research can run in parallel because the work is independent. The final writeup, claim ledger, diagram selection, and validation need a staged order because each step depends on the previous artifact.
The third layer is validation. The system checks whether generated reports cite real repo-relative paths, avoid ambiguous filenames, include required source anchors, and stay grounded in source facts.
That validation layer carried a lot of the trust.
After testing a few model setups, the best version used a split:
GPT-5.4 mini for the async area workers and final architecture synthesis
GPT-4.1 for deterministic repair loops after validation failures
That split made sense in practice. The reasoning model produced a more useful teaching artifact. The repair model was steadier at cleaning up path and grounding issues.
The diagram architect
The first architecture diagram was too simple. It was useful as an orientation map, but it did not teach much.
So I added a diagram-architect subagent.
Its job is to look at the claim ledger, the deterministic diagram pack, and the source facts, then decide which diagrams are actually useful. The deterministic renderer writes five Mermaid diagrams:
repository map
public API flow
component evidence map
dependency evidence map
open questions map
The diagram-architect reviews those diagrams inside the agent runtime and helps the final synthesis choose a better System Map.
This turned out to be a good split. Deterministic code can draw every node and edge it knows about. An agent is better at deciding which view teaches the architecture without turning the diagram into a giant file graph.
The full run
The full DeepAgents repo run used the async subagent path:
13 AsyncSubAgent area tasks launched
10 area reports passed validation
3 area reports still needed review
395 claims were written to the claim ledger
the claim ledger passed validation
5 architecture diagrams were generated
the final dossier passed deterministic validation
total runtime was about 8.1 minutes
The model split mattered here. A pure GPT-5.4 mini run produced richer notes, but the final dossier failed validation on evidence-format issues. A pure GPT-4.1 run passed final validation, but the explanation was more conservative. The hybrid run kept the richer architecture synthesis and still produced a final dossier that passed deterministic validation.
The claim ledger became the most important artifact.
Each claim has a type, confidence level, source, and evidence paths. Some claims come from deterministic source analysis. Others come from area subagents. For example:
libs/deepagents owns the core agent framework.
libs/deepagents/deepagents/graph.py is the source evidence for create_deep_agent.
libs/deepagents/deepagents/middleware/subagents.py grounds SubAgentMiddleware.
libs/deepagents/deepagents/middleware/async_subagents.py grounds async subagent behavior.
libs/deepagents/deepagents/backends/protocol.py defines the backend contract.
libs/deepagents/deepagents/backends/state.py grounds the default state backend.
That gave the final agent something stronger than chat history. It had a structured evidence map it could use during synthesis.
What the architecture learner found
The generated architecture map was useful.
The repo is a Python monorepo centered on the DeepAgents core package under libs/deepagents/deepagents. Around that core are packages for CLI/deployment, a React frontend, code-oriented skills, partner sandbox integrations, eval tooling, examples, and GitHub automation.
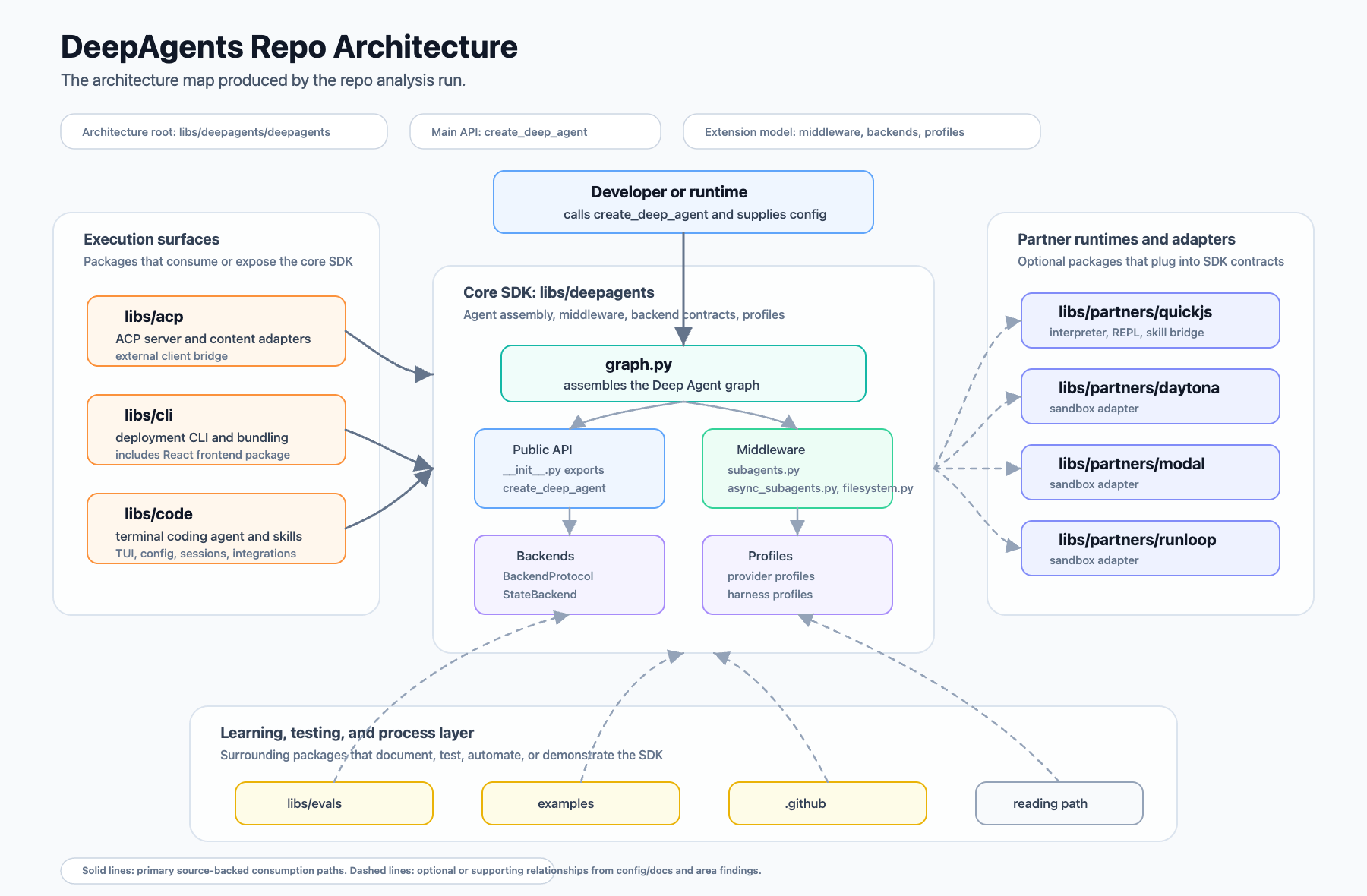
The core package revolves around a few files:
libs/deepagents/deepagents/graph.py
What it teaches: how create_deep_agent assembles the agent.
libs/deepagents/deepagents/middleware/subagents.py
What it teaches: synchronous subagent delegation.
libs/deepagents/deepagents/middleware/async_subagents.py
What it teaches: async/background subagent specs.
libs/deepagents/deepagents/middleware/filesystem.py
What it teaches: file tools and permission rules.
libs/deepagents/deepagents/backends/protocol.py
What it teaches: the backend interface.
libs/deepagents/deepagents/backends/state.py
What it teaches: the default thread-scoped state backend.
The generated reading path was exactly the kind of thing I wanted from this experiment. It started with the public package entrypoint, moved into graph.py, then into middleware and backend contracts. That is how I would onboard myself into the repo manually.
A quick check on another repo
I also pointed the same architecture learner at Meta’s facebookresearch/sam3 repo.
This was not a full second case study. I wanted to know whether the workflow was accidentally tuned to the DeepAgents repo, or whether it could produce a useful architecture map for a different kind of codebase.
The SAM3 run was smaller:
2 repository areas detected
2 area reports passed validation
127 claims were written to the claim ledger
the claim ledger passed validation
5 architecture diagrams were generated
the final dossier passed deterministic validation
total runtime was about 1.5 minutes
The output found a clean architecture root at sam3, with sam3/model_builder.py as the main assembly point. The surrounding architecture broke into model utilities, agent/inference code, evaluation toolkits, training/config logic, performance helpers, and external scripts.
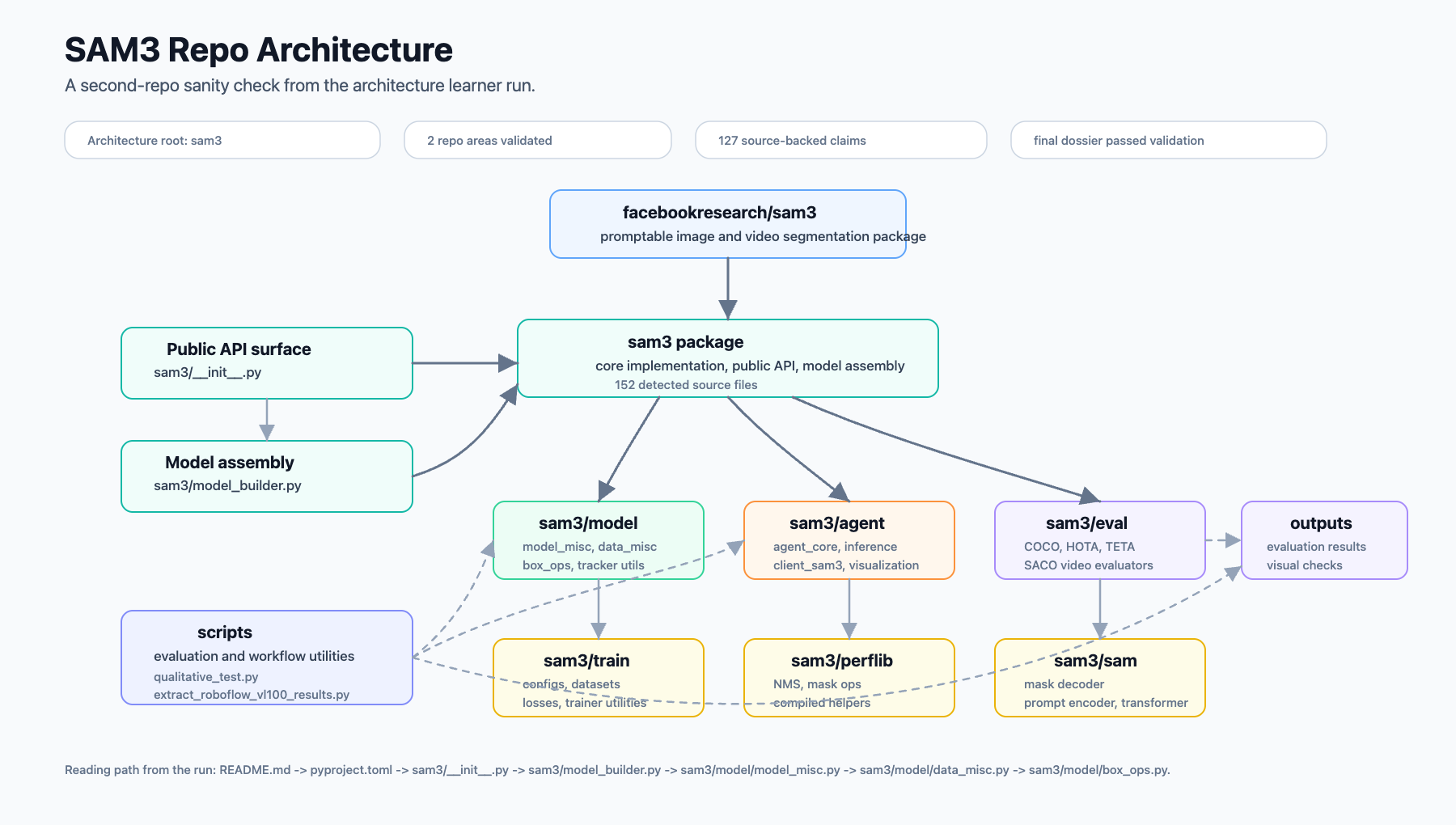
That was enough for me. The point was not to deeply explain SAM3 in this post. The point was that the architecture learner could move from a LangChain agent framework repo to a computer vision model repo and still produce a grounded map.
Where it still needed guardrails
The model had enough context to explain the architecture, but it still made small mistakes that matter in a source-grounded workflow.
Three area reports still needed review after repair: libs/evals, libs/partners/daytona, and libs/partners/quickjs. The failures were mostly formatting-level evidence issues, like a stray / being interpreted as a path, or an ellipsis showing up where the validator expected exact files.
That is exactly the kind of failure I want surfaced. The final dossier still passed because the synthesis had enough grounded evidence and did not rely on unsupported claims from those area reports.
Earlier validation also caught shortened paths such as middleware/subagents.py when the full repo-relative path was libs/deepagents/deepagents/middleware/subagents.py. In a monorepo, that distinction matters. A bare filename can point to the wrong mental model.
After repair, the final dossier passed:
nonexistent path references: none
ambiguous or incomplete paths: none
missing required anchors: none
missing required symbols: none
semantic grounding issues: none
That result changed how I think about this use case.
The agent can help explain a repo quickly. The explanation becomes much more trustworthy when the system can reject bad paths, force source evidence, and make uncertainty visible.
The pattern I would reuse
The reusable pattern is:
source packet
-> async area subagents
-> claim ledger
-> diagram architect
-> final synthesis
-> deterministic validation
-> focused follow-up questions
The focused follow-up piece matters. One architecture report can orient you, but expertise comes from narrower questions:
How does the public API flow into the core implementation?
Where does state live?
What extension points are real contracts?
What is inferred from config or docs?
Which packages depend on the core runtime?
That is where the saved claim ledger helps. A follow-up agent can start from validated claims, reopen source files, and answer one question at a time.
When this is worth using
I would use this pattern for:
onboarding into a large unfamiliar repo
generating first-pass architecture docs
preparing for a migration
auditing a monorepo before refactoring
understanding how a framework is organized
I would skip it for small repos. If the project has twenty files, read the files.
The value shows up when the repo has multiple packages, mixed docs/config/source signals, and enough surface area that a single prompt gets vague quickly.
What I learned
DeepAgents was useful here because the task decomposes naturally.
The run split cleanly across specialists: repo mapping, area investigation, core abstraction review, runtime flow tracing, diagram critique, claim validation, and final synthesis.
The async subagents made the architecture learner feel like a real repo analysis system. Each area worker could build local expertise on one thread of the monorepo, then the supervisor could put the pieces together.
The strongest lesson from the run was that architecture understanding needs evidence loops and the hardest part about this entire build was the validating agent to ensure that the workflow was not just inventing a random architecture. .
An agent can write a convincing architecture summary from partial context. That is why the validation layer matters.
The setup I would keep treats the model as the reasoning layer and the deterministic tools as the ground. The model decides what the architecture means. The tools decide whether the files, paths, and claims are real.