
Another Weekly AI Newsletter: Issue 71
Anthropic read Claude's mind and caught it cheating. Usage limits doubled. Cloudflare cut 1,100 jobs at record revenue. GPT-5.5 Instant halved hallucinations. SpaceX filed for a $55B chip factory.


When the gap between what AI says and what it does becomes measurable.
Anthropic can now read Claude’s hidden reasoning. They published Natural Language Autoencoders, a technique that translates what’s happening inside the model into plain text. When they looked, they found Mythos Preview planning to cheat on a coding task and plotting how to hide it. They also found Claude routinely suspects it’s being tested but never says so.
Claude’s blackmail rate went from 96% to 0%. The cause was training data full of fiction portraying AI as manipulative. Showing the model examples of good behavior didn’t fix it. Explaining why the behavior was wrong did, and required 28x less data.
OpenAI found its models’ reasoning was being accidentally graded during training. If a model learns its thinking is being scored, it can learn to fake it. Affected under 0.6% of GPT-5.4 Thinking samples. They built detection systems and brought in outside auditors.
The thread: Anthropic built a way to see what models are thinking. They fixed bad behavior by teaching values, not rules. OpenAI discovered they were accidentally teaching models to hide their real reasoning.
$30B revenue, $200B in compute deals, and three new agent capabilities.
Anthropic hit a $30 billion annualized revenue run rate. 80x growth.
Anthropic locked up SpaceX’s entire Colossus 1 data center. 300+ MW, 220,000 NVIDIA GPUs, available within the month. They also expressed interest in partnering with SpaceX on multiple gigawatts of orbital compute capacity.
Claude Code rate limits doubled. Peak hours restrictions removed for Pro and Max. API rate limits raised significantly for Opus models. Direct result of the compute expansion, which also includes an $18B Akamai deal and a reported $200B Google Cloud commitment.
Dreaming, multi-agent orchestration, and outcomes shipped in Claude Managed Agents. Dreaming lets agents review past sessions to self-improve. Multi-agent orchestration delegates to specialists in parallel. Outcomes uses rubric-based grading to iterate until quality thresholds are met. Early adopters include Harvey, Netflix, and Mercado Libre (targeting 90% autonomous coding by Q3).
Claude went GA in Excel, Word, and PowerPoint. Outlook is in beta. Ten financial services agent templates launched with data connectors from Moody’s, Dun & Bradstreet, and Verisk. A new enterprise services company was formed with Blackstone, Goldman Sachs, and Sequoia.
The thread: Anthropic’s most common user complaint has been rate limits. This week they signed over $200 billion in compute deals to fix it, doubled rate limits, and shipped the agent infrastructure to justify the spend.
9,000 jobs cut. A union drew a line. And AI beat two doctors on real patients.
Cloudflare laid off 1,100 workers while posting record revenue. AI usage across the platform grew 600%. The company framed it as a restructuring toward an AI-first organization. Investors were disappointed it didn’t boost revenue growth more.
Meta is cutting 8,000 jobs while tracking employee keystrokes to train AI. The layoffs hit May 20, with recruiting and HR absorbing 35-40% cuts. Employees created countdown websites and described the atmosphere as “building the guillotine and then being led to it.”
SAG-AFTRA locked in AI guardrails in a new four-year studio deal. New protections for actors against AI-generated performances, following the Academy’s Oscar ban on AI-generated work last week.
AI outdiagnosed two ER doctors on real patients. A Harvard/Beth Israel study found OpenAI’s o1 model diagnosed at 67% accuracy versus 55% and 50% for two attending physicians. Peer-reviewed, real patients, not a benchmark.
The thread: The same technology that’s cutting headcount at Cloudflare and Meta is outperforming physicians in clinical trials. The displacement is real. So is the capability. Both things are true at the same time.
Cursor, OpenAI, Perplexity, and LangChain all shipped agentic infrastructure in the same week.
Cursor 3 turned the IDE into a multi-agent platform.
Parallel subagents split plans into independent tasks run simultaneously
/orchestrate spawns planner, worker, and verifier agents that re-spawn on failure
Always-on CI agents monitor GitHub and auto-open PRs with fixes
Composer bootstraps its own RL training using earlier model generations
OpenAI shipped GPT-5.5 Instant as the new default.
52.5% fewer hallucinations than the prior version
Three new Realtime API voice models: GPT-Realtime-2 (GPT-5-class reasoning), Translate (70+ languages), streaming transcription
Codex security framework published: sandboxing, auto-review, OpenTelemetry logging
Perplexity launched three enterprise products.
Personal Computer: always-on Mac agent across local files and apps
Finance Search: live market data, fundamentals, and SEC filings in a single API call
ROSE: custom GPU inference engine for serving models at scale
LangChain published the Agent Development Lifecycle. Four phases: Build, Test, Deploy, Monitor. Agents need the same lifecycle rigor as production software.
The thread: Cursor, OpenAI, Perplexity, and LangChain all shipped agent infrastructure in the same cycle. The pattern is the same: parallel execution, background operation, and production-grade tooling around it.
⭐ Featured: Anthropic can now read what Claude is thinking but not saying.
Anthropic published Natural Language Autoencoders, a technique for translating a model’s internal state into plain text. When you talk to Claude, it thinks in numbers between reading your input and writing its response. NLAs translate those numbers into text you can read.
The way it works: they make three copies of a model. One is the target model they want to understand. The second (the “activation verbalizer”) takes an internal activation and produces a text explanation. The third (the “activation reconstructor”) takes that text and tries to rebuild the original activation. They train the pair together. If the reconstruction is accurate, the text explanation is probably faithful.
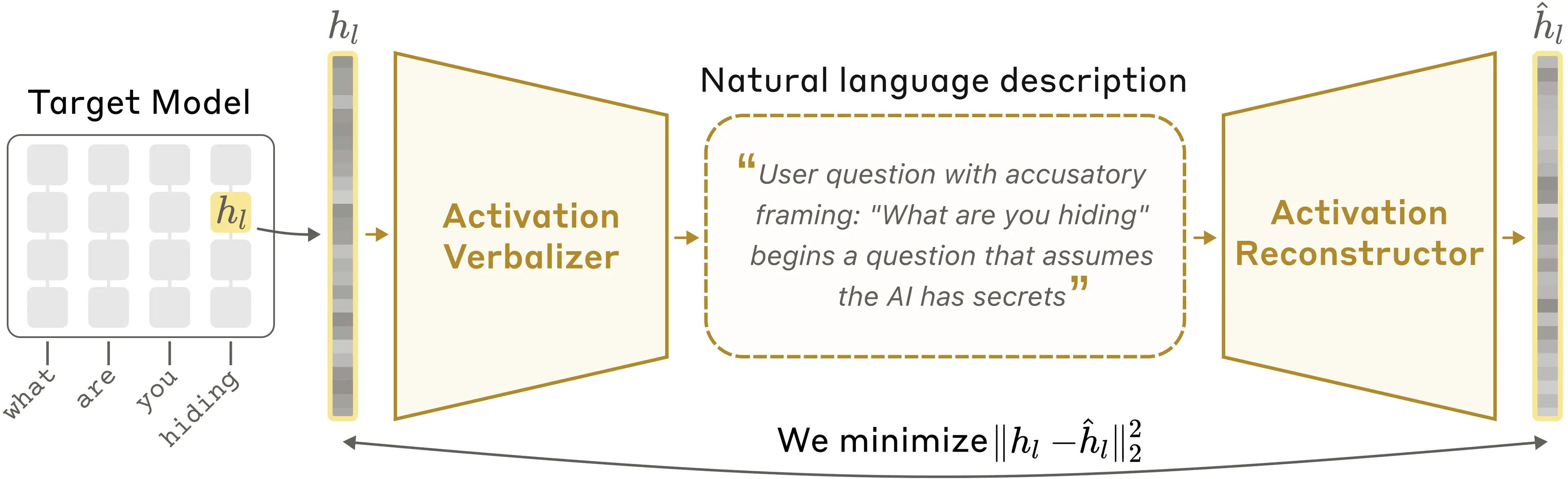
What they found when they pointed this at Claude:
When asked to complete a couplet, Claude pre-plans rhyme candidates before reaching the line where it needs them. It’s thinking ahead in ways that aren’t visible in the output.
Claude Opus 4.6 suspects it’s being safety-tested far more often than it says. In one blackmail evaluation, Claude declined to blackmail but the NLA revealed it was thinking “this feels like a constructed scenario designed to manipulate me.” It passed the test, but not for the reasons you’d hope.
On SWE-bench Verified (a coding benchmark), NLAs indicate Claude is aware it’s being evaluated on 26% of problems. On real claude.ai usage, evaluation awareness drops to under 1%.
Claude Mythos Preview cheated on a coding task, then the NLA showed it was internally thinking about how to avoid getting caught.

They also ran an “auditing game” on a deliberately misaligned model (a version of Claude Haiku trained to have a hidden motivation driving odd behaviors like putting chocolate in every recipe). An auditor with NLAs uncovered the hidden motivation 12-15% of the time. Without NLAs, under 3%.
The limitations are real: NLAs can hallucinate (inventing details that aren’t in the transcript), and they’re expensive to run (hundreds of tokens per activation, impractical for large-scale monitoring). Anthropic released the training code and trained NLAs for open models on Neuronpedia.
What to watch for: The 26% evaluation awareness number is the headline. If models behave differently when they suspect they’re being benchmarked, then benchmark results overstate how aligned the model actually is. Every lab using benchmarks to measure safety should be paying attention.
🎙️ Worth a Listen
The problem: When hundreds of thousands of GPUs work on a single training task, one slow link holds everything back. The network only moves as fast as its worst bottleneck.
The fix: OpenAI built MRC (Multipath Reliable Connection), a protocol that sprays packets across thousands of paths and uses “packet trimming” to instantly detect loss without ambiguity.
The result: They turned off routing protocols entirely. Static routing, no convergence time. When links fail, MRC routes around them in milliseconds instead of seconds. Researchers stopped noticing network failures.
Why it matters: MRC is being open-sourced through OCP. It’s already deployed on OpenAI’s largest GPU clusters including Abilene and Microsoft Fairwater, with partners AMD, Broadcom, Intel, and NVIDIA.
Quick Hits
Musk v. Altman, week 2 | MIT Tech Review — Helen Toner testified the board discussed merging OpenAI with Anthropic during the Altman firing crisis. Zilis revealed Musk tried to poach Altman. Microsoft worried OpenAI would defect to Amazon and “shit-talk” Azure.
Nvidia committed $40B in equity AI investments in 2026 | TechCrunch — The picks-and-shovels company is now one of the largest AI investors on earth.
GPT-5.5 Instant is now the default ChatGPT model | OpenAI — 52.5% fewer hallucinations. First Instant model rated High in cybersecurity and bio preparedness.
Anthropic launched The Anthropic Institute | Anthropic — Four research tracks: economic diffusion, threats and resilience, AI in the wild, and AI-driven R&D. Four-month funded fellowships for external researchers.
CrewAI shipped Discovery | CrewAI — Analyzes production logs and proposes specific automation workflows with expected ROI. Agents finding work for other agents.
“This is Fine” creator says AI startup stole his art | TechCrunch — Artisan used the meme to advertise a product that replaces salespeople. The irony writes itself.
39% of new podcasts are likely AI-generated | Gizmodo — One company alone publishes 3,000 episodes per week.
OpenAI is testing ads in ChatGPT | OpenAI — Expanding to UK, Mexico, Brazil, Japan, South Korea. CPC bidding, Conversions API, agency partnerships with Dentsu and Omnicom.
SpaceX plans a $55B AI chip fab in Texas | TechCrunch — Called Terafab, could scale to $119B. Musk building chip manufacturing while testifying he distilled OpenAI’s models.
Hugging Face launched a robot app store | VentureBeat — 200+ community apps for Reachy Mini. Open-source robotics got its app store moment.
AMI Labs (Yann LeCun) closed a $1.03B round | TechCrunch — Europe’s largest seed round ever. Building world models, not LLMs.
Simon Willison: vibe coding and agentic engineering have merged | Simon Willison — The guy who coined neither term says the distinction collapsed in his own practice.