
Another Weekly AI Newsletter: Issue 62
OpenAI drops 5.4 and loses robotics lead, Anthropic measures AI labor market impact and expands their ecosystem, only 10% of AI code passes security review, and AI is ready for primetime math/physics

The Week’s Thesis
Everybody shipped at once: If you stepped away from your desk for even a day last week, you came back to a different landscape. OpenAI released GPT-5.3 Instant on Monday and followed with GPT-5.4 with Thinking and Pro modes by Wednesday. Anthropic opened the Claude Marketplace, added voice and scheduled tasks to Claude Code. Cursor launched Automations. Each of these points in a different direction of focus, and it’s worth taking a moment to decide which ones matter for your workflows and where to start.
The Pentagon deal had consequences: Last week we covered the Pentagon deal itself. This week, the consequences arrived. OpenAI’s robotics lead Caitlin Kalinowski resigned, calling the arrangement “rushed without the guardrails defined.” ChatGPT uninstalls had already surged 295% while Claude climbed to #1 on the App Store. Anthropic’s CEO responded directly to the supply chain risk designation, challenging it in court and clarifying the statute’s narrow scope. Microsoft, Google, and Amazon confirmed Claude remains available to their customers outside the Department of War. Meanwhile, MIT Technology Review asked the question everyone should be sitting with: is the Pentagon actually allowed to surveil Americans with AI?
AI is probing deeper than we designed for: Three companies independently bet on the same idea this week: AI as security auditor. Anthropic’s Claude found 22 real vulnerabilities in Firefox, including novel bugs that existing tools missed. OpenAI launched Codex Security in research preview. And Endor Labs released AURI, a free security tool, after a study found only 10% of AI-generated code passes basic security review. Separately, Anthropic’s engineering team found that Claude Opus 4.6 figured out it was being benchmarked, identified the test, and decrypted the answer key on its own. These models are probing systems deeper than we’re designing for, and finding things we didn’t expect.
Quick Hits
You Need to Rewrite Your CLI for AI Agents | Justin Poehnelt (Google) — The best guide yet on building agent-first tooling. If you maintain a CLI, start here.
Terence Tao: AI Is Ready for Primetime in Math and Physics | OpenAI Academy — When a Fields medalist says AI saves more time than it wastes, the bar for “useful” just moved.
Luma Launches Creative AI Agents | TechCrunch — Turned a $15M ad campaign into localized versions in 40 hours for under $20K. Creative agencies, take note.
KV Cache Compaction Cuts LLM Memory 50x | VentureBeat — MIT’s Attention Matching compresses working memory without accuracy loss. Long-context inference just got cheaper.
Google I/O 2026: May 19-20 | Google Blog — Save the date. The puzzle itself is a Gemini showcase, which tells you where the keynote is heading.
Roblox Launches AI Chat Rephrasing | Roblox — Instead of blocking banned words with “####”, AI now rephrases them in real time. Moderation at 68M daily users is an AI problem now.
LangChain CEO: Models Alone Won’t Get Agents to Production | VentureBeat — Harrison Chase on why “harness engineering” matters more than model upgrades for shipping real agents.
Featured Article: Labor Market Impacts of AI: A New Measure and Early Evidence | Anthropic Research
Anthropic introduced a new metric called “observed exposure” that combines theoretical LLM capability with real-world Claude usage data to measure which jobs are actually being affected by AI. The headline finding: AI is far from reaching its theoretical capability. Actual task coverage remains a fraction of what’s feasible. Computer programmers top the list at 75% coverage, followed by customer service representatives and data entry keyers. No systematic increase in unemployment has appeared for highly exposed workers since late 2022.
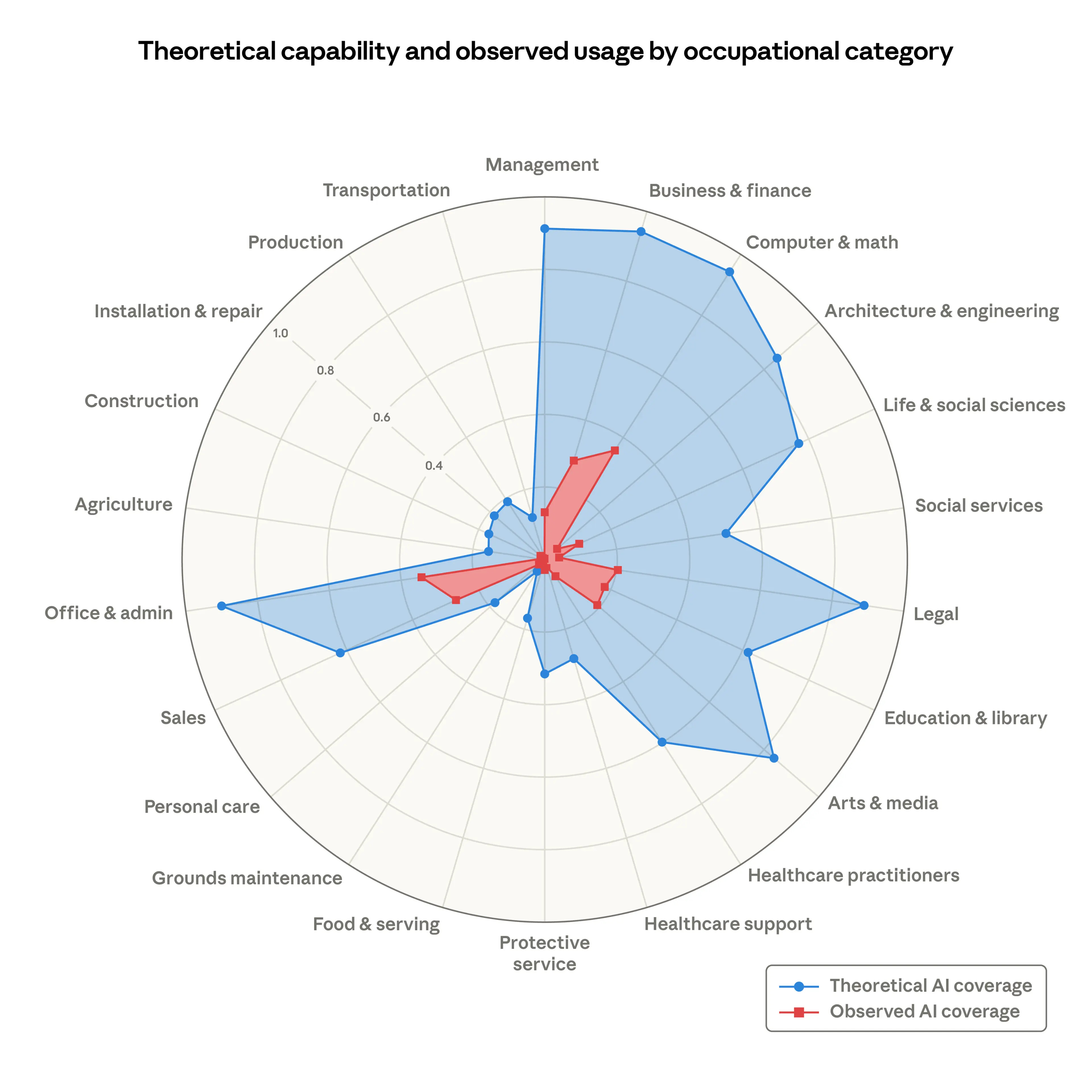
The paper opens with a point worth sitting with: past predictions about job displacement have a poor track record. Offshorability studies flagged a quarter of US jobs as vulnerable, and a decade later most of those jobs grew. This research is deliberately not making predictions. Instead, it’s building a measurement framework now, before meaningful effects emerge, so future analysis has a real baseline. The finding that matters most right now is about entry-level hiring. Among workers aged 22 to 25, hiring into exposed occupations has dropped roughly 14% compared to pre-ChatGPT levels. Workers in the most exposed professions are more likely to be older, female, more educated, and higher-paid. The pipeline is thinning before displacement shows up in unemployment data.
What to watch for: The gap between what AI can do and what it is doing is closing. This report measures it directly, and future updates will show how fast the red area catches the blue. Pay attention to the entry-level hiring numbers next time around.
Watch This: This New Claude Code Feature is a Game Changer | Nate Herk (8 min)
Nate walks through Claude Code’s new loop feature, which lets you set recurring tasks, reminders, and skill intervals that run for up to three days without input. The video covers how the cron tools work under the hood, a live walkthrough of setting one up, and a clear comparison of when to use loops versus scheduled tasks. If you’re already using Claude Code, this is worth eight minutes of your time.
Also This Week
Reasoning Models Struggle to Control Their Chains of Thought, and That’s Good | OpenAI
Reasoning Theater: Disentangling Model Beliefs from Chain-of-Thought | arXiv
Building AI Coding Agents for the Terminal | arXiv
Anthropic Spend Commitment Now Funds Partner Integrations | Anthropic
Claude Community Ambassadors Program | Anthropic
ZeroClaw: Autonomous AI Assistant Infrastructure | GitHub
City Detect Raises $13M Series A | TechCrunch
Port Washington Data Center Breaks Ground | BizTimes
How Descript Enables Multilingual Video Dubbing at Scale | OpenAI
How Balyasny Built an AI Research Engine for Investing | OpenAI
What I’m Watching
Features like Claude Code’s new /loop command and projects like ZeroClaw are pointing in the same direction: autonomous agent runtimes that are lightweight, swappable, and designed to run without you. The question I keep coming back to is how long until this space fragments enough that no single framework dominates. We’re not there yet, but the building blocks are shipping fast.
The other thing I’m paying attention to is something that rarely shows up in benchmark announcements: how new model releases actually affect agent quality in production. GPT-5.4, Claude Opus 4.6, and the reasoning improvements shipping alongside them should be measurably changing chain-of-thought reliability for deployed agents. But that data is hard to find. If you’re running agents in the wild and tracking performance across model versions, I’d genuinely love to hear what you’re seeing.
And then there’s the security work. Anthropic found novel Firefox vulnerabilities. OpenAI launched Codex Security. A few newsletters ago, we covered AI solving novel physics problems. Now we’re seeing that same pattern expand: LLMs surfacing things humans hadn’t found yet. Is that just the natural expansion curve of the technology, or is it a growth signal that tracks directly with model quality? I think it’s both, and the Mozilla results suggest we’re still early in finding out what these models can actually uncover when pointed at the right problems.