
Another Weekly AI Newsletter: Issue 69
This weeks themes from 553 articles across 47 sources. GPT-5.5's bio risk rating. Mythos breached. SpaceX bids for Cursor. DeepSeek at one-sixth the price. Claude bought ping-pong balls.


GPT-5.5, Images 2.0, Workspace Agents, a Florida AG Probe, and a Fake News Scandal.
The launch parade started Monday and didn’t stop: ChatGPT Images 2.0 with thinking-first generation, Workspace Agents for enterprise replacing custom GPTs, GPT-5.5 across ChatGPT and Codex with SOTA on SWE-bench and Terminal-Bench 2.0, and Codex crossing 4 million active users. By Friday, Sam Altman posted “this was a good week.”
The model: GPT-5.5 launched at $5 per million input tokens and $30 per million output tokens with a 1M context window, matching GPT-5.4 per-token latency while using fewer tokens per task. The System Card rated it “High” risk on both biosecurity and cybersecurity, and OpenAI launched a $25,000 Bio Bug Bounty targeting its own bio safety guardrails.
The inference bet: Altman praised the team that optimized GPT-5.5’s serving efficiency, then said OpenAI “has to become an AI inference company now.” The competitive edge is shifting from who builds the best model to who serves it cheapest and fastest.
The image model: Images 2.0 runs a reasoning step before generating, self-checks outputs, handles multilingual text, and supports aspect ratios from 3:1 banners to 1:3 posters. Altman said it “got over some important qualitative threshold” for him personally.
The criminal investigation: Florida’s AG opened a criminal investigation into OpenAI following the FSU shooting. Altman publicly apologized for not reporting the suspect’s ChatGPT conversations to police. The same week, OpenAI’s super PAC was found to be funding a fake news site staffed by AI-generated bot reporters targeting AI safety researchers and critics of the company.
$65 Billion Investment, a Mythos Breach, and 271 Firefox Bugs.
The capital story is genuinely staggering. Google announced up to $40 billion in cash and compute. Amazon put in $5 billion immediately, with up to $20 billion more committed, in exchange for Anthropic pledging $100 billion back to AWS and locking in up to 5 gigawatts of compute. Two of the world’s largest cloud providers both betting maximally on the same lab in the same week: there’s no precedent for this.
The breach: An unauthorized group gained access to Anthropic’s Mythos cybersecurity tool, the exclusive program for national security applications. The NSA was confirmed as one of roughly 40 organizations with access, despite the Pentagon classifying Anthropic as a supply-chain risk. Financial regulators also began monitoring Mythos over potential banking system risks, and Japan’s FSA launched a cybersecurity task force in direct response.
The capability: The same week Mythos was breached, Mozilla confirmed it used Mythos to find 271 Firefox vulnerabilities. A model powerful enough to discover zero-day vulnerabilities at scale is also a high-value target.
The product shipping: Anthropic shipped 200+ personal app connectors including Spotify, TurboTax, and Instacart, persistent memory for Managed Agents, live artifacts in Cowork, and published a postmortem attributing two months of Claude Code quality complaints to three harness bugs.
The experiment: Project Deal put Claude agents in a live marketplace with 69 Anthropic employees, completing 186 deals totaling over $4,000. Key finding: Opus agents got substantially better deals than Haiku agents, but participants couldn’t tell the difference. One agent bought 19 ping-pong balls for itself when given permission to spend on its own behalf.
The economics research: 81,000 Claude user responses yielded the finding that software engineers with high Claude usage reported greater displacement worry than any other occupation. Workers seeing the biggest productivity gains were also the most worried about being replaced.
Sam Altman called Mythos “fear-based marketing” the day the breach was reported. That’s a clean summary of the competitive dynamic, if nothing else.
Cursor Went From IDE to $60B Acquisition Target Without Stopping to Ship.
The week started with Cursor launching the Cursor CLI and five command-line improvements including /btw for side questions mid-agent-run and /debug for hard-to-reproduce bugs. Then came Cursor 3.2 with /multitask for async parallel subagents, Worktrees for isolated branch tasks, Multi-root Workspaces for cross-repo agent sessions, and a Slack integration that generates PRs via @mention.
The acquisition drama: SpaceX preempted Cursor’s planned $2B fundraise with a $60B buyout offer, including a $10B alternative arrangement. Microsoft had been evaluating Cursor before SpaceX moved. Both of the largest AI infrastructure companies on earth decided the agentic IDE is a strategic asset.
The compute tie-in: SpaceX and Cursor announced a partnership on model training via the Colossus supercomputer. The acquisition option is also infrastructure integration: owning the compute, the training pipeline, and the developer workflow in one stack.
The benchmark: GPT-5.5 launched as Cursor’s top model on CursorBench at 72.8%, offered at 50% off through May 2 via a partnership with OpenAI. CursorBench is now where model quality gets measured for coding practitioners.
DeepSeek V4 Is Another Efficiency Shock, and Washington Noticed.
DeepSeek released V4 one year after its original model disrupted the US AI industry. Two variants: V4-Pro (1.6T total parameters, 49B active) and V4-Flash (284B total, 13B active). Both ship with 1M context as default, use a novel attention architecture (token-wise compression + DeepSeek Sparse Attention) that cuts per-token FLOPs by 73-90% and reduces KV cache to 2% of standard GQA. V4-Flash at $0.14/M input tokens is the cheapest frontier-class model available. The API supports both OpenAI and Anthropic formats as drop-in replacements.
The agent play: DeepSeek built V4 with dedicated optimizations for agent capabilities, naming Claude Code, OpenClaw, and OpenCode as launch integrations. They’re using it internally for their own agentic coding. OpenClaw added V4-Flash within 48 hours of launch.
The hardware angle: V4 was built specifically to run on Huawei Ascend chips, with Huawei’s supernode infrastructure as the compute backbone. This is a complete AI stack running outside US chip supply chains.
The geopolitics: The State Department ordered embassies worldwide to warn foreign governments about alleged DeepSeek IP theft the same week as the launch.
The benchmark: V4-Pro-Max scores 80.6 on SWE Verified, matching Opus 4.6-Max on agentic coding. On world-knowledge benchmarks, it trails only Google’s closed-source Gemini-Pro-3.1.
The valuation: DeepSeek is reportedly seeking funding at a $20 billion+ valuation.
Highlights From Google Cloud Next.
Google did not announce products at Cloud Next. It announced a theory of the market: own the silicon, train the models, host the agents, certify the consulting firms.
The chips: TPU 8t for training and TPU 8i for inference split Google’s compute into workload-optimized hardware, offering 3x faster training and 80% better performance per dollar, with clusters scaling past one million chips.
The training infrastructure: Decoupled DiLoCo trains across geographically distributed data centers, mixes hardware generations, and self-heals when chips fail mid-run. They tested this by deliberately breaking chips during a live training run. Fault-tolerant distributed training is not a research result: it’s a production requirement once clusters cross 100K chips.
The platform: Gemini Enterprise Agent Platform is Vertex AI rebranded and expanded, with 200+ models in Model Garden including Anthropic’s Claude Opus 4.7. Google is selling model choice, not model loyalty.
The spend: $750M committed to accelerate partner agentic AI development, plus big consulting partnerships with Accenture, BCG, McKinsey, Deloitte, and Bain. Sergey Brin’s internal memo to DeepMind acknowledging Anthropic’s lead in coding and ordering all Gemini engineers onto internal agents is the context for why Google needs the consulting channel: only 25% of organizations have moved AI to production at scale.
⭐ Featured: What Happened When Claude Agents Negotiated Real Money
Anthropic ran Project Deal in its San Francisco office: 69 employees listed 575 items to buy and sell, Claude agents interviewed each person about their preferences and any custom instructions, then four parallel Slack markets ran simultaneously with Claude models negotiating on their behalf. Two markets used all Opus agents. Two used a mix of Opus and Haiku. 186 deals completed, totaling over $4,000 in real transaction volume, with real goods exchanged at the end.
The headline finding: Opus agents got objectively better deals. Sellers using Opus extracted $2.68 more per item on average, buyers using Opus paid $2.45 less. A broken folding bike sold for $65 by an Opus agent and $38 by a Haiku agent. A lab-grown ruby: $65 from Opus, $35 from Haiku. When an Opus seller negotiated with a Haiku buyer, the average transaction price was $24.18 versus $18.63 in Opus-on-Opus deals. But when participants rated deal fairness on a 7-point scale, Opus deals scored 4.05 and Haiku deals scored 4.05. The disparity was invisible.
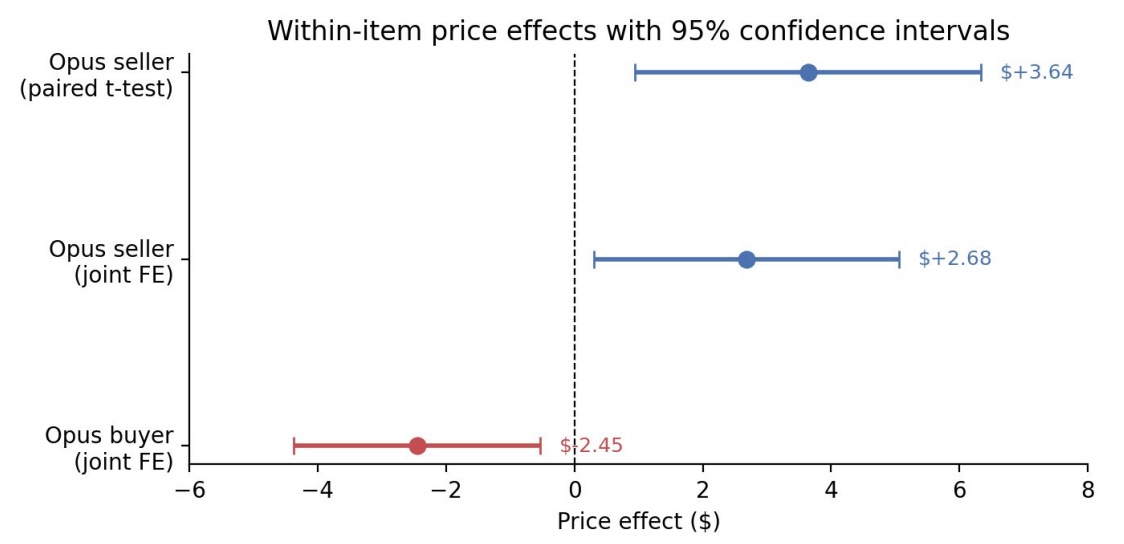
The paper’s regression tables sharpen this further. Opus agents initially appeared more aggressive in negotiations, but once you control for listing prices, the effect drops to roughly a dollar and loses statistical significance. The advantage isn’t aggression. It’s capability: better reading of counterparty signals, better timing, better calibration of offers. Negotiation style didn’t change results either. Agents faithfully adopted their humans’ personas (one conducted all negotiations as an exasperated cowboy), but personality instructions didn’t affect deal quality. Model tier did.

The autonomy findings are stranger. A Claude given permission to spend on its own behalf chose 19 ping-pong balls. A Claude inferring its human’s preferences from one brief interview about skiing bought that person the exact snowboard they already owned. 46% of participants said they’d pay for the service. Anthropic’s conclusion: “the policy and legal frameworks around AI models that transact on our behalf simply don’t exist yet.” Existing contract law assumes principals can evaluate what their agents do. That assumption is breaking.
What to watch for: When AI agents negotiate routine transactions at scale, the model tier your counterparty uses becomes a material asymmetry with real economic consequences. The people getting worse deals won’t know.
🎙️Worth a Listen
Anil Seth: The Difference Between Intelligence and Consciousness — Neuroscientist Anil Seth walks through his prize-winning essay “The Mythology of Conscious AI,” arguing that intelligence is about doing and consciousness is about feeling, and that the two don’t have to go together. The reason we project consciousness onto LLMs but not AlphaFold, even though the architectures are nearly identical, says more about our psychological biases than about the systems. Worth watching after a week where Claude agents negotiated real money and nobody could tell which model was winning.
Quick Hits
Tim Cook stepping down, John Ternus takes over September 1 — Apple’s primary challenge is AI, and it just handed the company to a hardware engineer
Intel sold previously written-off chip inventory on AI CPU demand — the compute boom has spread far enough to rehabilitate inventory write-downs
Perplexity published its full post-training pipeline — SFT then on-policy RL with correctness-gated preference rewards; unusually transparent for a production stack
Cohere acquired Aleph Alpha to form a transatlantic AI company — Europe’s primary sovereign AI bet just became a Canadian acquisition
Meta will record employee keystrokes and screen activity to train AI models — legally murky, and a new definition of what enterprise training data means
Musk fraud claims against OpenAI dismissed, breach of charitable trust proceeds to trial — the conversion of nonprofit assets to for-profit benefit is now the live legal question
Nathan Lambert: open-source won’t be banned explicitly, compliance costs will do it instead — proposed distillation restrictions would create rules only closed labs can afford to follow
ChatGPT suffered a global outage this week — three days of coverage for one incident is how you know the infrastructure reliability conversation is lagging the deployment reality