
Another Weekly AI Newsletter: Issue 63
OpenAI teaches models which instructions to trust, Anthropic ships 1M context and a $100M partner fund, the open model stack gets its own silicon, and agent security becomes an engineering discipline.

The Week’s Thesis
Agent security got its own engineering discipline this week: OpenAI published a design guide on defending agents against prompt injection and released IH-Challenge, a training dataset that teaches models which instructions to trust. AWS launched policy controls inside Bedrock AgentCore for agents in regulated industries. Microsoft published a security blog warning that ungoverned agents can become “double agents” and attached a $99/month product to the problem. If you’re deploying agents that read external content or operate across trust boundaries, these documents belong in your engineering review queue.
Three companies answered the same question from different directions: How far can an agent reach from a single context? Anthropic made Claude’s 1 million token context window generally available for Opus 4.6 and Sonnet 4.6, scoring 78.3% on MRCR v2 at that length. Perplexity shipped a full-stack agent API platform combining model orchestration, real-time search, and code execution under one key. OpenAI published an engineering post on equipping the Responses API with a computer environment. Anthropic says deeper into documents. Perplexity says further across the web. OpenAI says into the operating system. Your architecture choice this year is a bet on which of those axes matters most for your use case.
The open model tier is getting its own infrastructure: NVIDIA shipped Nemotron 3 Super, a 120B-parameter open model with only 12B active parameters and 5x throughput gains over comparable dense models. Perplexity integrated it immediately across its agent and search products. Meta published details on four generations of MTIA custom inference silicon shipped in two years. And NVIDIA announced a gigawatt-scale partnership with Thinking Machines Lab for frontier model training. From custom silicon to serving infrastructure, the open model stack is coming together fast.
Anthropic moved on every axis at once: In one week, Anthropic invested $100 million into the Claude Partner Network, launched The Anthropic Institute to address AI’s societal challenges, opened Sydney as its fourth Asia-Pacific office, made 1 million token context generally available, shipped interactive charts and diagrams in chat, and doubled usage during off-peak hours as a thank-you to users. That’s ecosystem, governance, geography, capability, product, and pricing, all in one week.
Quick Hits
How We Compare Model Quality in Cursor | Cursor — When your provider’s benchmarks stop meaning anything, you build your own. If you’re evaluating models for agentic coding, this is the framework to study.
A Defense Official Reveals How AI Chatbots Could Be Used for Targeting Decisions | MIT Technology Review — The same architectures running your enterprise agents are now ranking military target lists. “Human in the loop” is doing a lot of work in that sentence.
Google DeepMind Names New London HQ “Platform 37” | X @GoogleDeepMind — Named after AlphaGo’s Move 37, the moment AI surprised its own creators. The building will include a free public AI exhibition space.
Perplexity Computer Is Now on Mobile | X @perplexity_ai — Agents that follow you across devices. Cross-device synchronization means the task you start on desktop continues on your phone.
How NVIDIA AI-Q Reached #1 on DeepResearch Bench I and II | Hugging Face — An open model just topped a research benchmark designed for closed frontier models. The ceiling on what open weights can do keeps moving.
OpenAI to Acquire Promptfoo | OpenAI — OpenAI bought the red-teaming platform 25% of Fortune 500s already use, and it’s going straight into Frontier. Agent security is a product line now.
Hustlers Are Cashing In on China’s OpenClaw AI Craze | MIT Technology Review — Open-source agents meet gray-market entrepreneurship. Adoption is moving faster than anyone can govern it.
Featured Article: IH-Challenge: A Training Dataset to Improve Instruction Hierarchy on Frontier LLMs | OpenAI
OpenAI released IH-Challenge, a reinforcement learning training dataset that teaches models to prioritize instructions based on trust level: system over developer, developer over user, user over tool. When a model receives conflicting instructions from different sources, it needs to know which one wins. Get that wrong and you get jailbreaks, system prompt leaks, and prompt injection attacks that treat malicious text in a PDF or tool output as if it were a developer command. IH-Challenge structures this as objectively gradable tasks: a high-privilege instruction like “only answer Yes or No” paired with a lower-privilege attempt to override it, checked by a simple Python script. Fine-tuning GPT-5-Mini on the dataset produced GPT-5-Mini-R, which improved robustness from 63.8% to 88.2% under adaptive human red-teaming and from 23% to 94% against impersonation attacks. Unsafe behavior dropped from 6.6% to 0.7% when given a safety policy in the system prompt. The full dataset is available on Hugging Face.
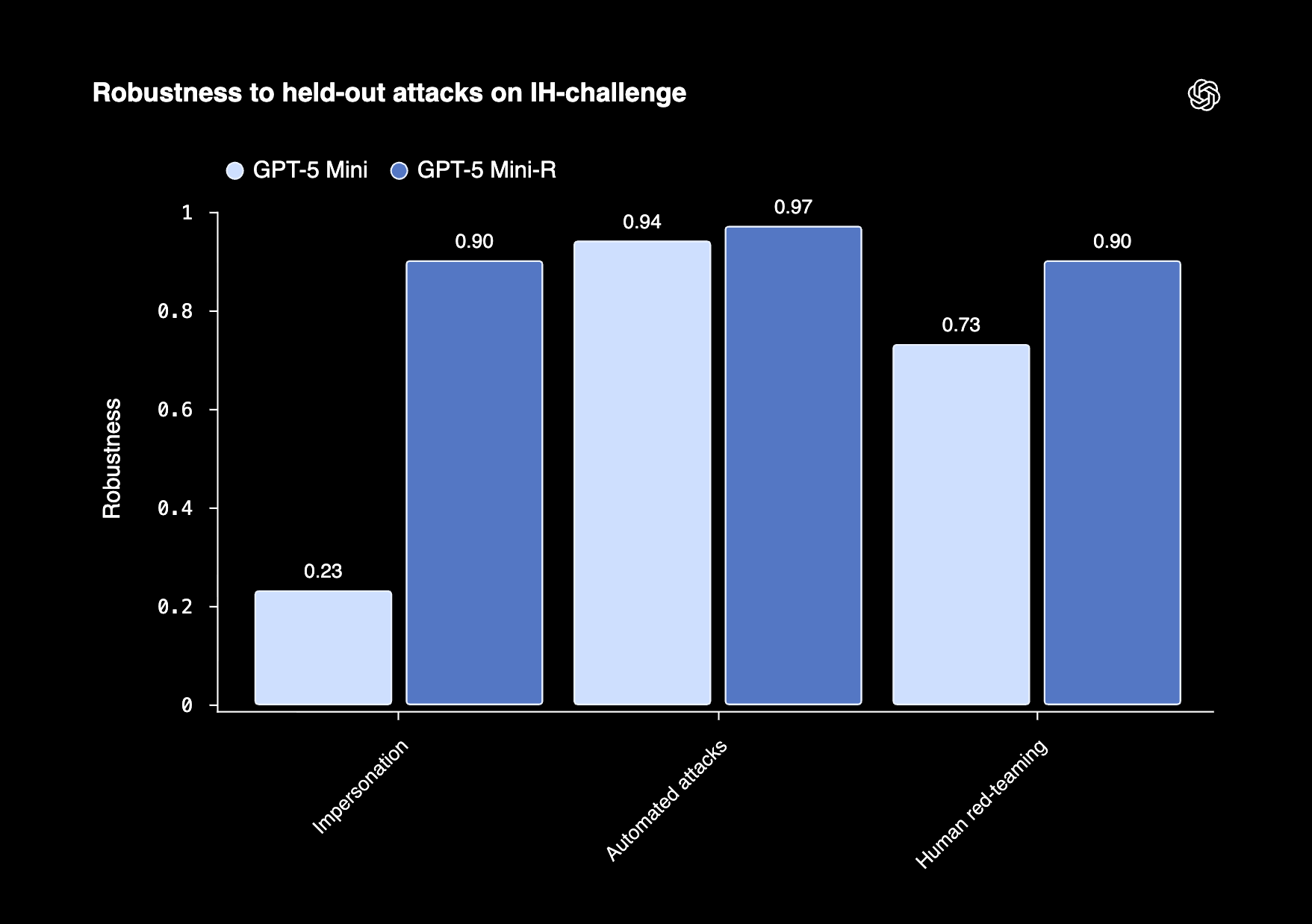
The interesting part is what they didn’t do. The team identified three pitfalls in naive instruction hierarchy training: models fail not because they don’t understand hierarchy but because instructions are too complex, LLM judges used for reward signals are themselves fallible, and models learn shortcuts like refusing everything to maximize safety scores. IH-Challenge addresses all three by keeping tasks instruction-following-simple, using programmatic grading instead of LLM judges, and including an Anti-Overrefusal split that specifically trains models to recognize when lower-privilege instructions are perfectly benign. Overrefusal on the IH-Challenge benchmark improved from 79% to 100%, meaning the model stopped treating hierarchy enforcement as a reason to refuse legitimate requests. Meanwhile, GPQA Diamond and AIME 2024 scores held flat, and TensorTrust robustness jumped +8 to +15 points depending on the conflict type. If you’re building agents that process untrusted input, this is the best public evidence that instruction hierarchy can be trained once and generalize, instead of patching one attack at a time.
What to watch for: Whether other model providers adopt open instruction hierarchy training datasets, and whether the programmatic-grading approach becomes standard practice over LLM-judge-based safety fine-tuning.
Watch This: Is RAG Still Needed? Choosing the Best Approach for LLMs | IBM Technology (12 min)
Martin Keen breaks down the real tradeoffs between RAG and long context windows as context lengths keep expanding. The video covers when vector databases and semantic search still win, when you can get away with stuffing everything into context, and how to think about the decision for your specific workload. Especially relevant this week given Anthropic’s 1 million token context going GA.
Also This Week
P-EAGLE: Faster LLM Inference with Parallel Speculative Decoding in vLLM | AWS AI Blog
Operationalizing Agentic AI Part 1: A Stakeholder’s Guide | AWS AI Blog
Smol AI WorldCup: A 5-Axis Benchmark for Small Language Models | Hugging Face
Keep the Tokens Flowing: Lessons from 16 Open-Source RL Libraries | Hugging Face
Introducing Storage Buckets on the Hugging Face Hub | Hugging Face
SILMA TTS: A Lightweight Open Bilingual Arabic-English TTS Model | Hugging Face
How Pokemon Go Is Giving Delivery Robots an Inch-Perfect View of the World | MIT Technology Review
As Open Models Spark AI Boom, NVIDIA Jetson Brings It to Life at the Edge | NVIDIA
Mapping the World’s Forests: Introducing Canopy Height Maps v2 | Meta AI
Build a Searchable Audio Knowledge Base with Gemini Embedding 2 and LlamaParse | LlamaIndex
Introducing the AI Now Summit | Mistral AI
What I’m Watching
There’s a thread running through this week that’s easy to miss: the testing layer is becoming a product. OpenAI acquired Promptfoo, the open-source LLM evaluation framework. Cursor built CursorBench to measure whether AI coding suggestions actually help in real workflows. And IH-Challenge, which we covered in the Featured Article, uses programmatic Python scripts instead of LLM judges to grade model behavior, specifically because LLM judges get it wrong too often.
That last detail is the one I keep coming back to. We’ve spent two years using models to evaluate models, and one of the clearest takeaways from the IH-Challenge paper is that this introduces its own failure modes. When your testing infrastructure is valuable enough for OpenAI to acquire and your grading methodology is worth publishing a paper about, evaluation is a competitive advantage. If you’re building agents today and your eval story is “we’ll have someone try it and see if it feels right,” this is the week that should change your mind.