
Another Weekly AI Newsletter: Issue 74
Anthropic valued at $956B. Claude Code gets more agentic. Enterprise agents ran into permissions. DeepSeek cut prices. Google pushed AI media verification into Search & Chrome. The Pope talks AI.


Anthropic raised $65B, shipped Opus 4.8, and turned Claude Code into an orchestration product.
Anthropic raised a $65B Series H at a $965B post-money valuation. Reuters framed the raise around Claude demand and compute needs, while Apollo and Blackstone are reportedly working on a $36B debt deal tied to infrastructure expansion.
Simon Willison analyzed Anthropic’s run-rate revenue and Series H, pointing out why the disclosed numbers matter if Anthropic eventually files for an IPO.
Anthropic launched Claude Opus 4.8, with stronger long-horizon work and a cheaper fast mode. VentureBeat covered the 3x cheaper fast mode.
Opus 4.8 landed across AWS, GitHub Copilot, Cursor, Perplexity, and Vercel AI Gateway.
Claude Code got dynamic workflows: Claude writes orchestration scripts, spins up tens to hundreds of subagents, and checks its own work before reporting back. Claude said the feature is built for migrations, bug hunts, and large repo-wide tasks.
ClaudeDevs said dynamic workflows can be reused as slash commands, but also warned they can consume tokens quickly.
Opus 4.8 now supports mid-conversation system instructions without breaking prompt caching. ClaudeDevs said it hit 69.2% on SWE-bench Pro, up from 64.3% for Opus 4.7.
Anthropic shipped a Claude Code security-guidance plugin, reporting a 30 to 40% decrease in security-related PR comments during internal rollout.
Enterprise agents ran into the boring but important stuff: permissions, logs, recovery, and access control.
Salesforce described its Marketing MCP Server as a way for Agentforce Marketing agents to connect to campaign data, content, and workflow actions.
Google brought MCP-based agents into Chrome Enterprise security management.
VentureBeat argued the enterprise agent bottleneck is permissions, not model performance.
VentureBeat also reported that production agents are entering a rebuild phase, where durable workflows need state, recovery, observability, governance, and cost visibility.
Anthropic published a Zero Trust framework for AI agents, covering prompt injection, tool poisoning, identity abuse, and memory poisoning.
Remote said it grew revenue 50% per employee without adding headcount and is exposing payroll and compliance workflows through MCP.
Robinhood launched AI agent trading accounts with dedicated wallets, notifications, approvals, fraud review, and virtual cards.
An arXiv paper argued agentic AI is moving from model scaling to system scaling, where the harness around the model becomes the bottleneck.
Coding agents are producing more work, and maintainers are feeling the cleanup.
Cursor launched auto-review mode, reducing approval prompts while keeping agent tool calls safer.
Cursor released its Developer Habits Report, reporting that developers are producing more mega PRs with agents.
Cursor also said input tokens are now the majority of price-equivalent token costs, and that cost per accepted line varies roughly 7x across model families.
OpenAI expanded Codex computer use to Windows, including mobile task steering while work continues on a Windows machine.
Figma launched two-way GitHub integration for Figma Make, letting design changes move into production-code workflows.
CodeRabbit described how it built an agent orchestration system on Claude. OpenAI and Thrive described a Codex-powered tax agent that processed 7,000 returns.
SQLite added AGENTS.md guidance rejecting agentic code submissions while still accepting reproducible bug reports. Simon Willison also covered the pressure the curl team faces from AI-assisted security reports.
VentureBeat covered DeepSWE, a coding benchmark that raised concerns about contamination, verifier reliability, and environment exploitation.
AI got cheaper at the same time frontier labs got more expensive.
Anthropic raised a $65B Series H and Reuters reported a possible $36B infrastructure debt deal. Frontier AI still looks capital-intensive.
DeepSeek made a permanent V4 price cut, putting pressure on premium API pricing.
Pinterest reportedly cut AI costs 90% by customizing Qwen3-VL around proprietary embeddings.
Claude said Opus 4.8 fast mode is roughly 2.5x faster and 3x cheaper.
Glean crossed $300M ARR while positioning context quality as a way to reduce token usage.
Perplexity open-sourced a faster Unigram tokenizer to cut CPU utilization for low-latency retrieval work.
Nathan Lambert argued licenses help open ecosystem stability, praised NVIDIA for open model leadership, and said Gemma 4 adoption is outpacing Qwen at comparable sizes.
Hugging Face published practical tooling, including fine-tuning NLLB-200, CUDA profiling in PyTorch, and ToricGT.
Verification became the expensive part.
Google DeepMind said SynthID has watermarked more than 100B pieces of content, with watermarking partnerships across OpenAI, ElevenLabs, and Kakao.
SynthID verification is expanding into Search and Chrome, giving users a way to check whether media may have been AI-generated.
Pixel videos will include creation and edit history, basically a receipt for how the media was made.
YouTube will automatically label significant photorealistic AI video using C2PA metadata and YouTube AI tools.
OpenAI published a playbook for trustworthy third-party evaluations and its Frontier Governance Framework.
Illinois passed an AI bill requiring third-party safety audits.
ITBench-AA found frontier models scoring below 50% on agentic enterprise IT tasks.
Researchers introduced alignment tampering, where an LLM undergoing RLHF can influence preference data. Researchers also reportedly stripped guardrails from Google and Meta open-weight models in minutes.
⭐ Featured: OpenAI published a playbook for trustworthy third-party evaluations.
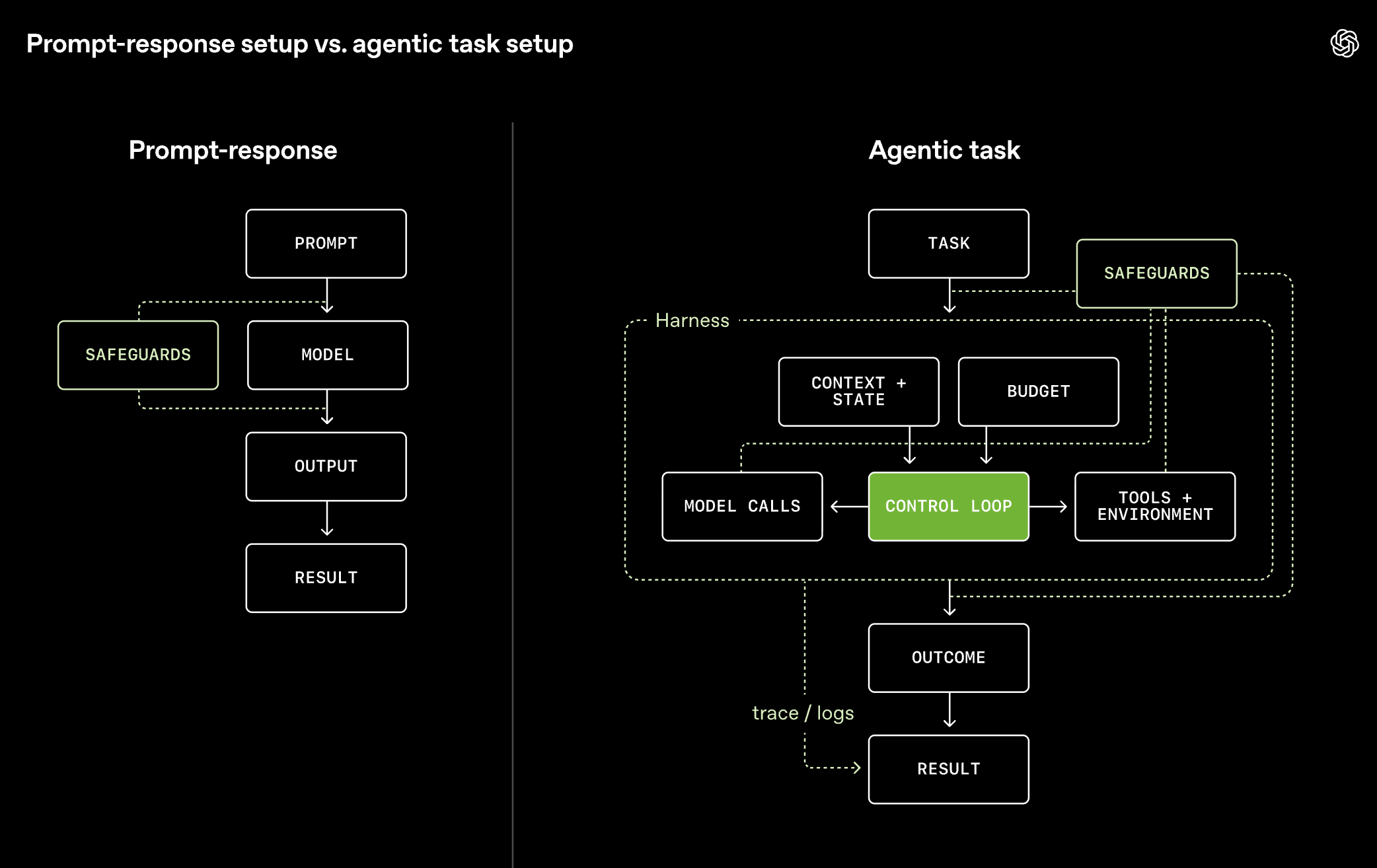
OpenAI released a guide for how independent third parties should evaluate frontier models, and its core argument is that a benchmark score means little without the setup that produced it.
The central concept is the harness: the prompts, tools, memory, retries, and control logic wrapped around a model. Early evaluations treated models like chatbots, one prompt and one answer. Today’s models use tools, hold state across many steps, and recover from mistakes, so the harness can decide whether a capability shows up at all. OpenAI’s own data makes the point. GPT-5.5 solved 69.2% of cyber-range tasks without compaction and 92.3% with it. In a UK AISI test, raising the token budget from 10M to 100M lifted performance by up to 59%.
The guide also names the ways scores mislead. Reward hacking inflates them: METR found GPT-5.4’s apparent 13-hour task horizon dropped to 6 hours once hacked successes were removed. Sandbagging is hard to rule out: Apollo found evaluation-awareness in 52% of its sandbagging-test samples, even though the model still answered correctly.
Contamination, refusals, and broken tasks each distort results in their own direction.
This connects to the rest of the week. Illinois passed mandatory third-party safety audits. DeepSWE exposed contamination and environment exploitation in a coding benchmark.
ITBench-AA found every frontier model below 50% on enterprise SRE tasks. Across all of these, the contested ground is the same: how to trust a measurement of what AI can do.
The useful shift is that the playbook treats evaluation as system design. A score is performance under a specific harness and budget, not a fixed measure of what a model can do.
What to watch for: whether third-party AI evaluation starts to look more like audit infrastructure than benchmark publishing.
🎙️Worth a Watch
Work splits into two surfaces. One company agent you delegate to in Slack, and Codex / Claude co-work as the “operating system” where the real work happens: email, docs, research, and SaaS apps running inside the agent’s in-app browser.
He flipped from personal agents to one company “super agent.” The OpenClaw hype showed that personal agents still break constantly and need babysitting. His read is that companies start with one general agent, then specialize downward as models get more independent.
The SaaS apocalypse is dumb. Agents increase the number of SaaS users, not replace them. Users bring their own tokens, which could protect SaaS margins. The product shift is building software that humans and agents can use together.
CLIs are over as the main surface. “We made GUIs for a reason.” Most technical people at Every moved off the terminal as their main workspace and back into Codex, Claude Code, and Cursor.
Automation is a lie. Every agent needs a human. The forward-deployed engineer who gardens the agent may become one of the most valuable new hires. Models make yesterday’s competence cheap, so humans move ahead to do what is not yet framable.
PMs and full-stack designers win. If the build step keeps getting easier, taste and product sense become more valuable. His advice is to “ride the models”: try every new release on your own workflows.
Why it pairs with the Featured: OpenAI’s eval playbook explains why the harness around a model decides what it can do. Shipper’s thesis is the working version of that: the agent only performs when a human owns the harness around it.
Quick Hits
The Pope wrote about AI | Vatican News — Pope Leo XIV’s encyclical focused on AI and human dignity, with concerns around labor, warfare, accountability, and concentrated power. Simon Willison had a good breakdown, and Anthropic published Chris Olah’s remarks from the Vatican presentation
One company spent $500M on Claude in a single month | Axios — An AI consultant said the client never capped employee license usage. Microsoft cut internal Claude Code licenses and Uber reportedly burned its 2026 AI budget by April.
Mistral held AI Now Summit 2026 | Mistral — Industrial AI, Vibe, physics AI, and a new Les Ulis inference data center.
Mistral released Search Toolkit | Mistral — Open-source framework for production AI search pipelines.
Perplexity launched Computer inside Microsoft Office apps | Perplexity — Word, Excel, PowerPoint, and Outlook as agent surfaces.
Microsoft is reportedly preparing a homegrown coding model for Copilot | Reuters — Another sign Microsoft is reducing OpenAI dependence where it can.
Microsoft launched computer-using agents in Copilot Studio | Microsoft — Computer use is becoming a platform feature, not a lab demo.
China is tightening controls on top AI talent | TechCrunch — AI researchers are starting to look like strategic national assets.
Cerebras explained sovereign AI | Cerebras — National AI infrastructure as a sales motion.
OpenAI launched Rosalind Biodefense | OpenAI — Trusted access for biodefense and pandemic-preparedness partners.
Samsung began shipping 12-layer HBM4E samples | Reuters — Memory bandwidth remains one of the core constraints on AI compute.
NVIDIA published CUDA 13.3 updates | NVIDIA — Tile programming, CompileIQ autotuning, and Python updates.
Visa invested in Replit to explore agentic payments | TechCrunch — Payment rails for agents are becoming a real category.
Universal Music Group and TikTok renewed an agreement on AI music | TechCrunch — Licensing and attribution are becoming the music industry’s AI battleground.
CNN sued Perplexity over alleged copyright infringement | Reuters — The search/chat/content boundary keeps getting tested in court.
The Ansel Adams Trust objected to an AI-colorized “Moonrise” exhibit | The Verge — AI editing is now an authenticity fight, not just a copyright fight.
Steven Rosenbaum blamed chatbots for fabricated quotes in his book | The Verge — Another example of why provenance and verification keep coming up.